Hadoop集群搭建
前言:搭建hadoop集群的博文很多,不能总是每次搭建时都花时间搜索一篇适合自己机器、文章简练清晰的教程,笔者也是描述自己搭建Hadoop集群的详细过程,以备日后使用。
一、准备及所需环境
Centos 6.5(目前大多数生产环境使用的较稳定版本)JDK 1.8.xVmvare Workstation
二、开始搭建
一般分布式集群都有多种搭建模式,Hadoop搭建的四种模式说明 :
本地模式:只是用于本地开发调试伪分布模式:同一台机器上各个进程上运行Hadoop的各个模块,各个模块是在各个进程上分开运行,但在一台机器。完全分布式模式:生产环境采用的模式,Hadoop运行在服务器集群上,企业会做HA,以实现高可用。Hadoop HA:HA是指高可用,解决Hadoop单点故障问题。
本地模式和伪分布模式都不适用于新手体验分布式的特点,没有太大意义,HA是企业级操作,遂本文以搭建完全分布式。
三台虚拟机分别为:
master:192.168.163.145
worker1:192.168.163.146
worker2:192.168.163.147
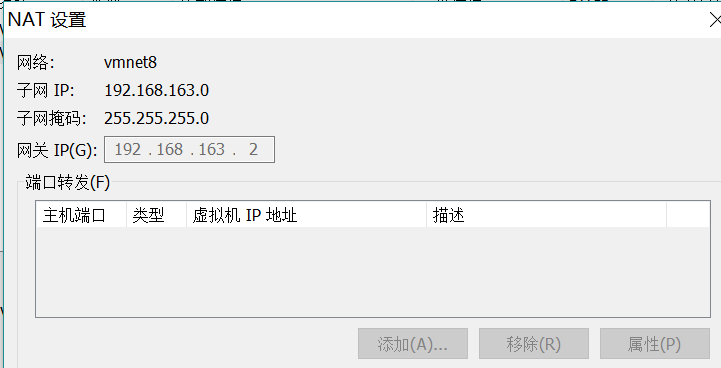
在这之前我们在Vmware中,点击编辑中虚拟机网络配置,查看NAT设置,记住子网IP和子网掩码,以及网关IP,会在配置网络时用到。
1.现在创建第一台虚拟机:
建议安装新建一个安装目录,并把每台虚拟机单独放在一个文件里,类似这样,不然所有虚拟机磁盘文件混在一起,非常乱。

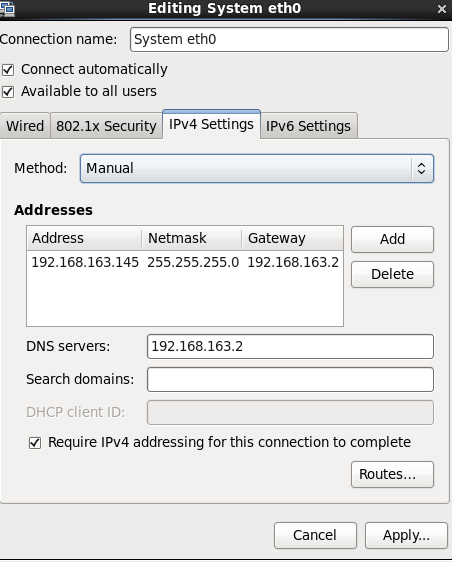
2.安装一路下一步,可能会要求你创建一个用户,这里我们先创建一个hadoop用户,密码自设,完成后打开虚拟机,这时候网络应该是不通的。由于我们选用的是NAT模式,可以共享宿主机的网络,但如果虚拟机网络设置为DHCP的话,IP会有租期,时间一到,DHCP会重新给你分配IP,这样就后期配的所有环境带来很大麻烦,所以我们设置为固定IP。
刚才记住的网关,子网掩码,以及DNS都配置上去, Address填写你自己网段下的没使用过的ip,我这里使用192.168.163.145
配置完成后,可以打开火狐浏览器看是否连上外网,也可命令行ping www.baidu.com
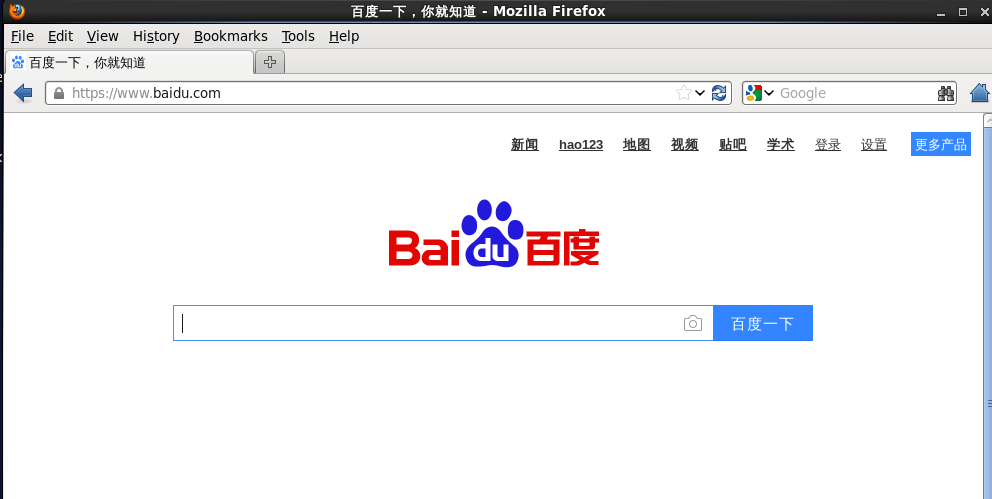
成功,至此网络配置结束。
3.修改Hostname及配置Hosts
两种方式:临时修改hostname: hostname master,这种方式重启就会失效,不建议。

永久修改:#vim /etc/sysconfig/network

配置 #vim /etc/hosts
另外两台机器虽然还没有创建,但在这直接配置好。

4.关闭防火墙
查看防火墙状态。
# service iptables status
临时关闭:# service iptables stop
永久关闭:# chkconfig iptables off(建议),重启生效
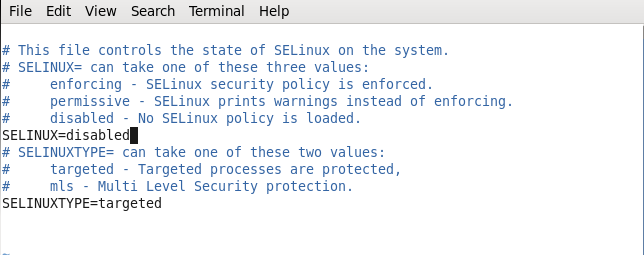
禁用掉selinux
# vim /etc/sysconfig/selinux
reboot,查看防火墙状态

5.安装JDK
首先为了大家linux环境下权限以及文件目录的整洁,建议大家以root用户在根目录下创建app目录并将所有权限赋给hadoop用户。
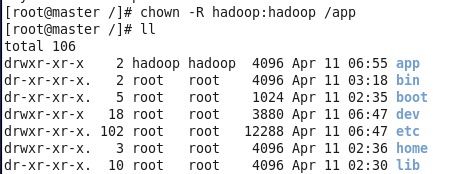
切回hadoop身份,下载好Oracle的jdk 1.8.x版本,传入虚拟机/app下
为了方便下面将开始使用xshell 5 连接 master进行操作
#tar -xzvf jdk1.8.0_141.tar.gz
添加到环境变量 #vim ~/etc/bash_profile
JAVA_HOME=/app/java/jdk1.8.0_141
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
保存退出 # source ~/.bash_profile
查看#java -version

为了方便,给hadoop增加sudo权限
#chmod u+w /etc/sudoers


6.克隆其他两个节点
右键克隆,创建完整克隆,新建文件夹worker1、worker2
打开worker1、worker2
依次改变ip 192.168.163.146、147
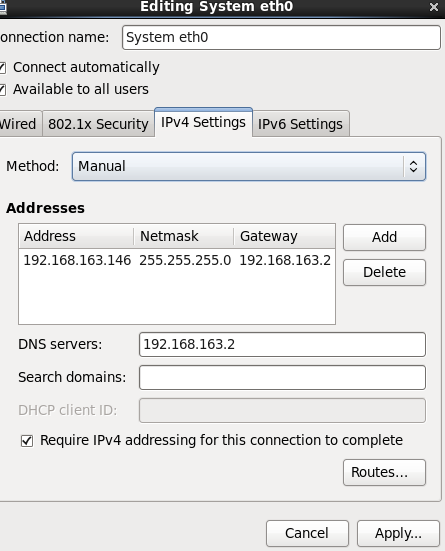
由于克隆将第一台机器的mac地址也保留了下来,所以将Auth eth1的mac地址复制到system eth0中的mac地址里,重启网卡
配置Hostname及hosts
worker1 、worker2 方法同上
7.安装Hadoop
在第一台机器上安装,hadoop官网下载hadoop2.7.0,如果下载过慢,可以选择国内的服务器,如清华大学镜像、中国科学技术大学镜像,阿里云,163等。
配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数,不配置hadoop找不到。
$ vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh,配置JAVA_HOME,运行#which hadoop
![70 17][]
进入hadoop配置文件
配置core-site.xml
配置hdfs-site.xml
配置yarn-site.xml
配置slaves集群
至此hadoop配置基本完成,接下来要三台机器需要通信,配置ssh
8.配置SSH通信
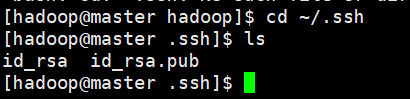
首先每一台机器上生成自己的公钥$ ssh-keygen -t rsa ,一直回车,全部默认,到当前hadoop用户下的.ssh文件夹里查看
在worker1和worker2分别运行
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub1
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub2
然后在master节点上运行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub1 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub2 >> ~/.ssh/authorized_keys
然后将authorized_keys分发到worker1和worker2
chmod 600 authorized_key
scp ~/.ssh/authorized_keys hadoop@worker1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@worker2:~/.ssh/authorized_keys
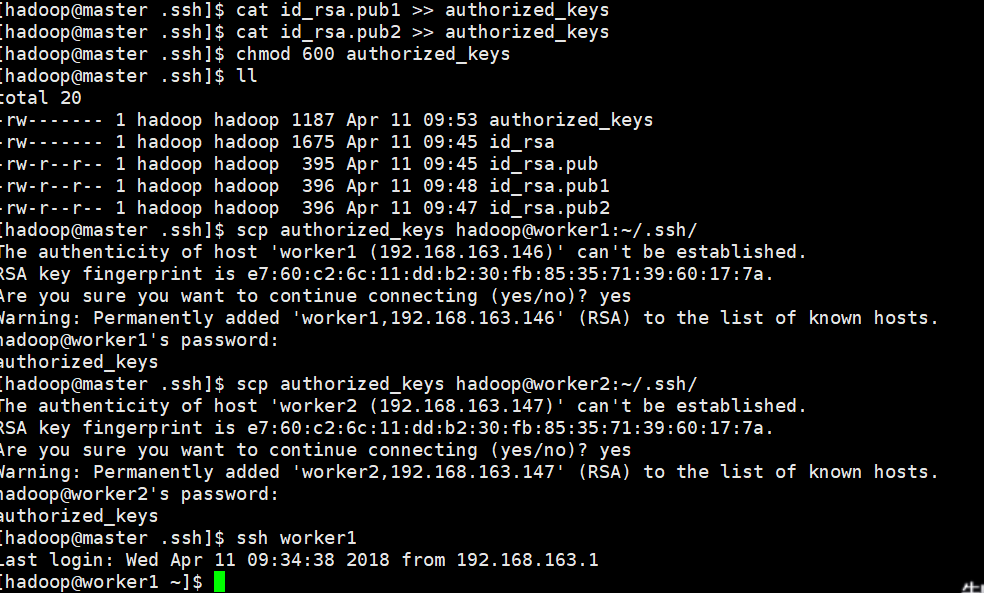
至此ssh通信配置完成。
创建hadoop的临时目录,三台机器均做。
$sudo -p mkdir /data/hadoop
同时给目录的所有者赋给hadoop用户,这部很重要,不然hadoop在格式化创建临时目录时会有权限问题
$sudo chown -R hadoop:hadoop /data
8.启动并验证
$hdfs namenode -format

不能有报错信息,且输出了namenode的临时文件以及一些文件信息。
启动hadoop集群
$ cd $HADOOP_HOME/sbin
你可以使用 $hadoop-daemon.sh start namenode
$hadoop-daemon.sh start datanode
或者 $start-dfs.sh
这里有可能会遇到问题
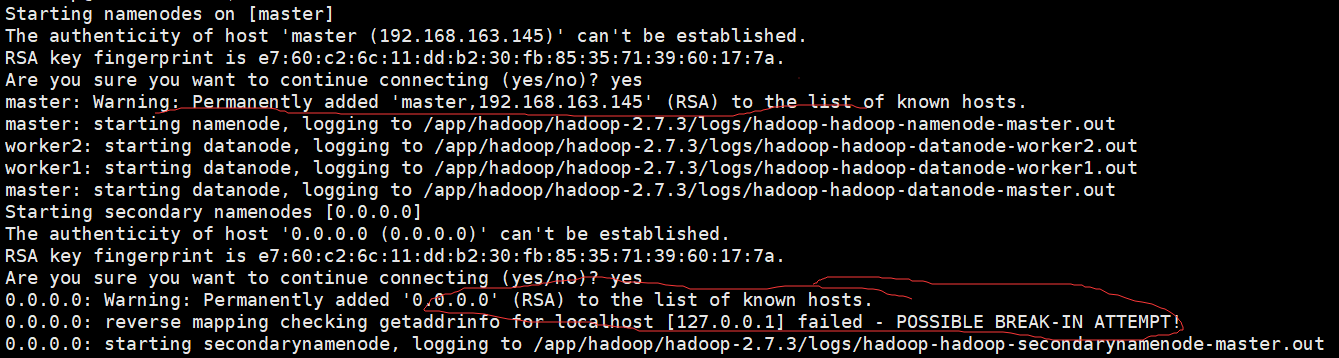
这是因为ssh连接检查出现了问题,也可以忽略不管,也可以$vim /etc/ssh/ssh_config
将GSSAPIAuthentication yes 改为 no
结束进程stop-dfs.sh重新启动
$jps 查看进程
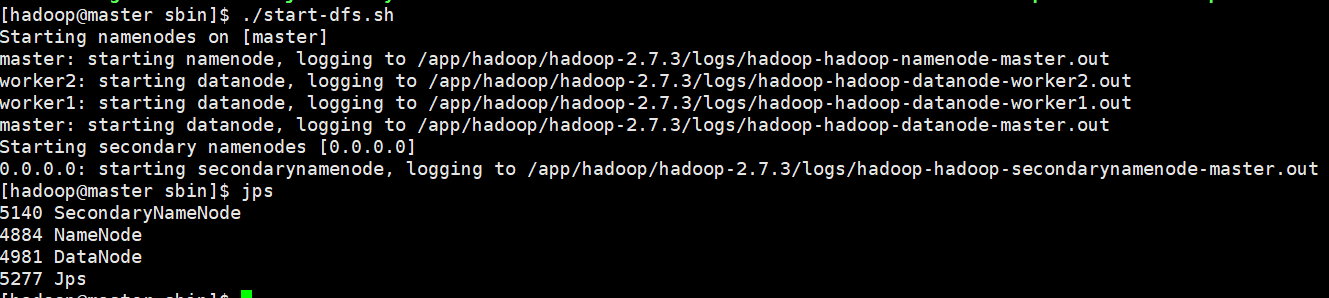

$start-yarn.sh 启动yarn进程,查看进程
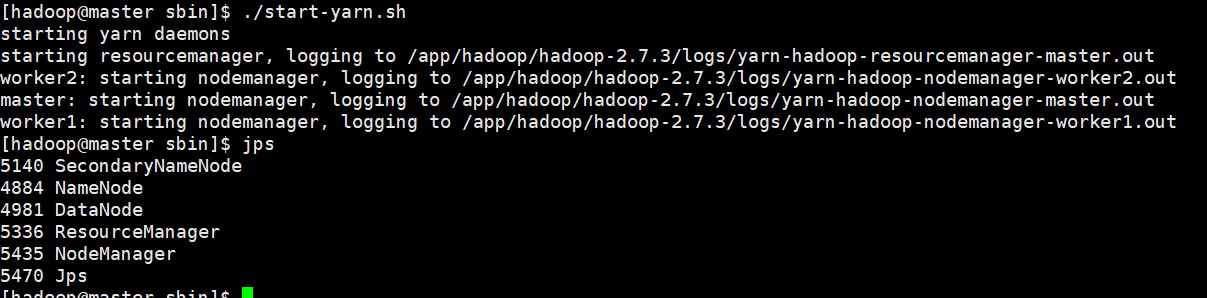

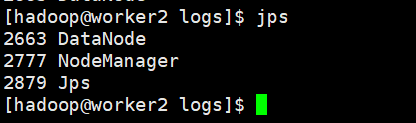
你也可以使用已经不建议使用的start-all.sh 和 stop-all.sh 一劳永逸。
至此hadoop集群启动完成,我们可以测试一下hdfs能否使用
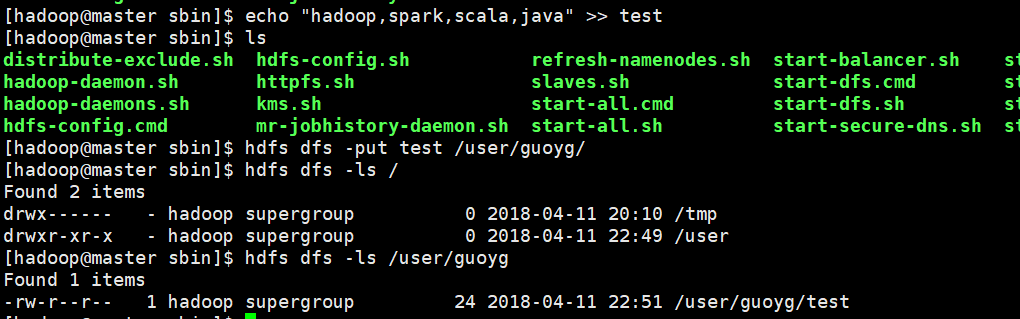
$hdfs dfs -mkdir /user/guoyg
$hdfs dfs -ls /
$echo “hadoop,spark,scala,java” >>test
$hdfs dfs -put test.txt /user/guoyg/
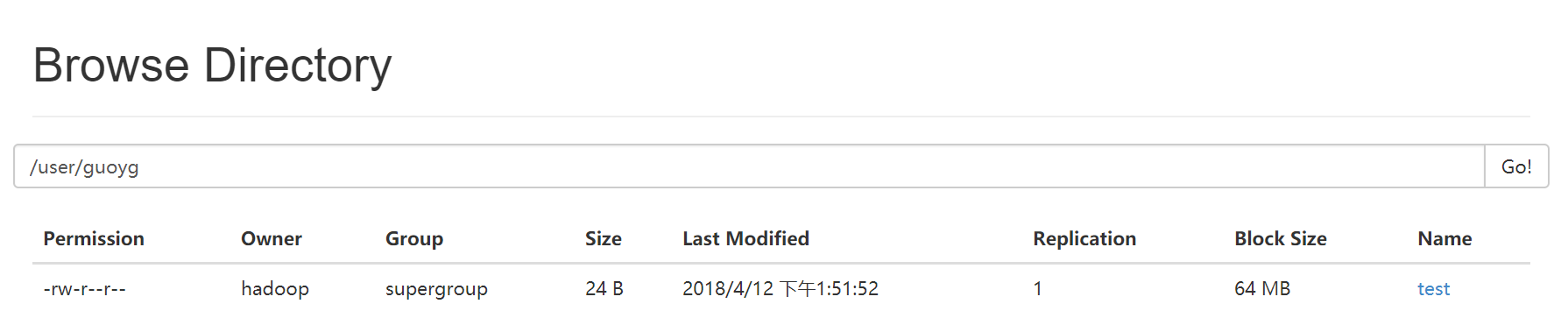
$hdfs dfs -ls /user/guoyg
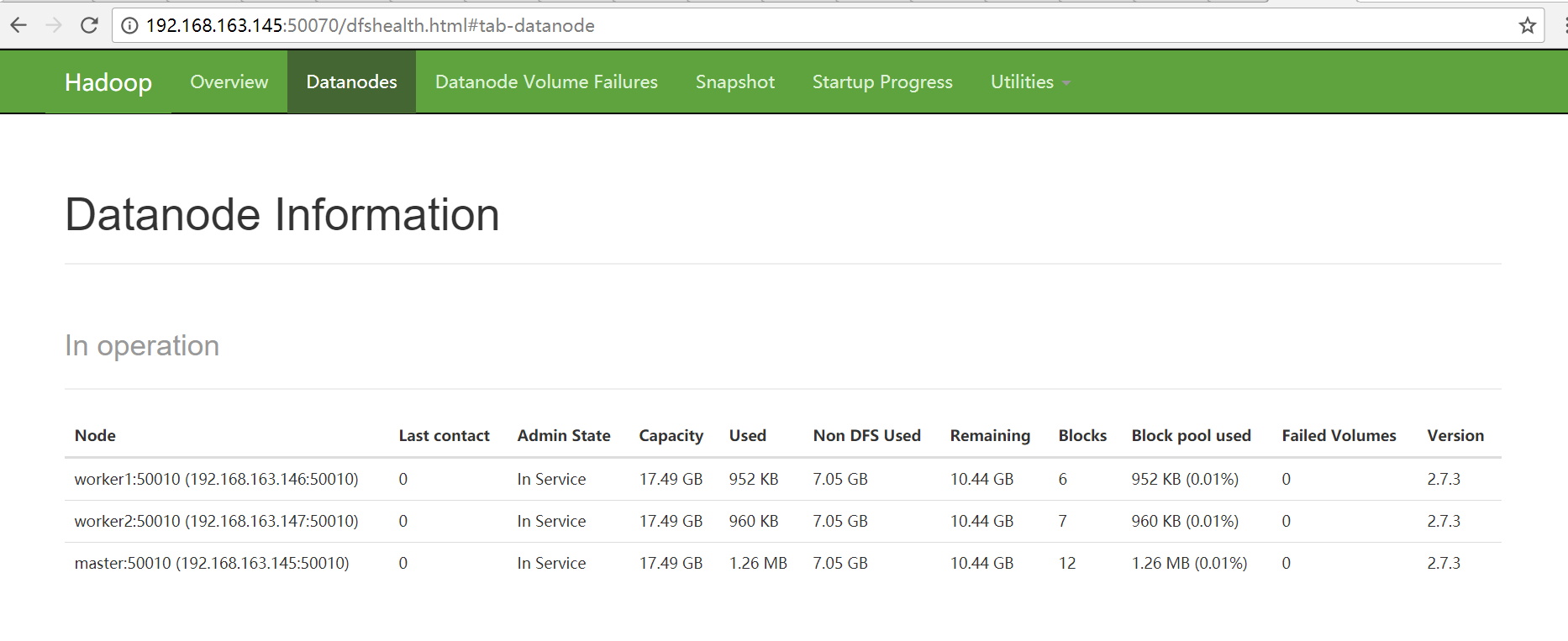
打开浏览器,linux和宿主机都可以,输入master节点的50070端口 :192.168.163.145:50070可看到如下:
查看192.168.163.145:8088应用程序管理界面
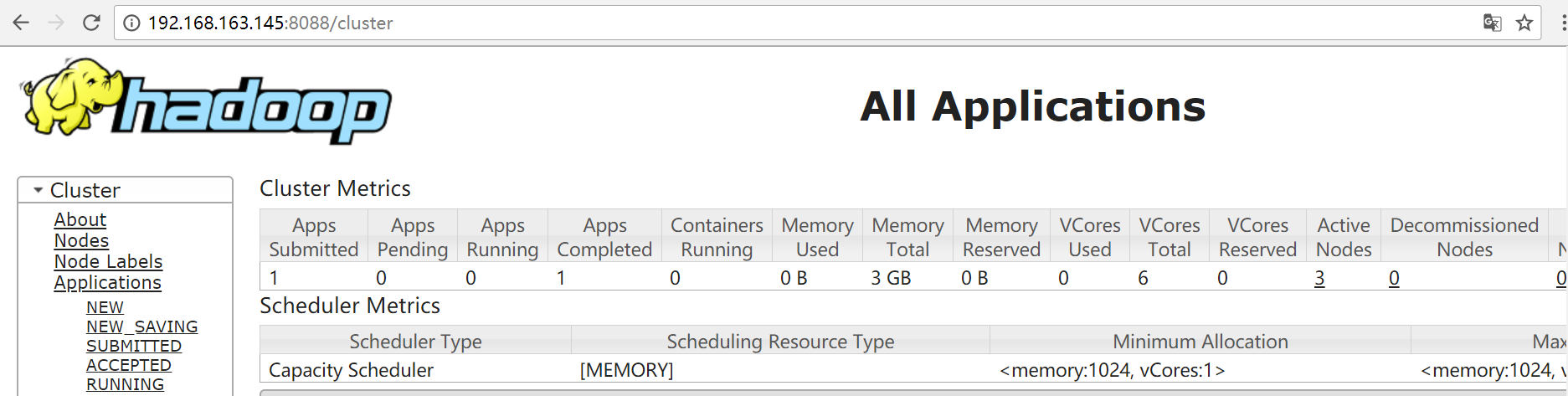
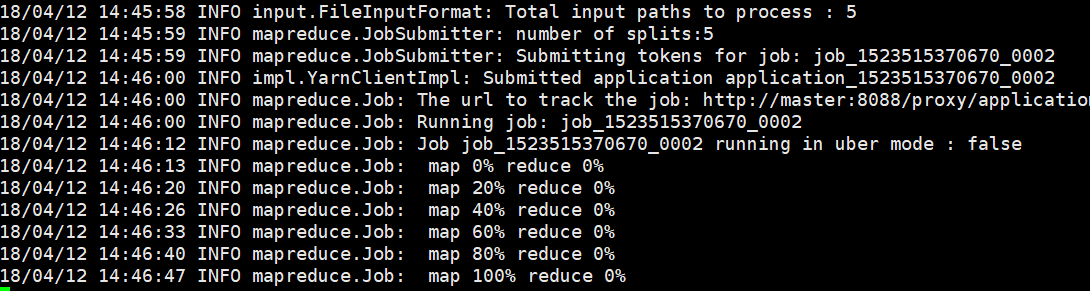
运行hadoop自带的exmaple计算圆周率。
$hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3 jar pi 5 5
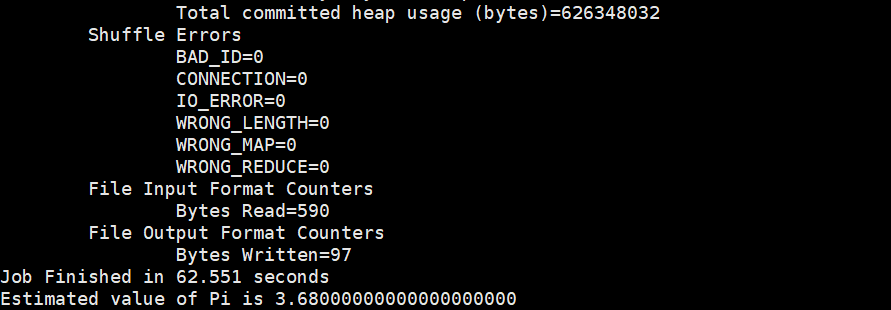
结果为3.680000000000000000
至此hadoop完全分布式配置完成。




























Gralloc与Framebuffer")




还没有评论,来说两句吧...