Hadoop集群搭建
环境:
CentOS7.4(CentOS-7-x86_64-DVD-1810.iso)
Hadoop3.2.0
jdk-8u201-linux-x64.tar.gz
VMware® Workstation 12 Pro
一、前期准备:
1.关闭防火墙
systemctl status firewalld // 查看状态
systemctl stop firewalld
systemctl disable firewalld // 删除开机启动
2.关闭SELINUX
vi /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
重启
检查是否关闭:
getenforce
3.修改主机名
主机1:hostnamectl set-hostname m1.example.com
主机2:hostnamectl set-hostname m1.example.com
4.SSH免密登录
在m1.example.com、m2.example.com添加对应关系:
vim /etc/hosts
192.168.76.134 m1.example.com
192.168.76.135 m2.example.com
注释掉:(否则会有子节点无法找到问题)
127.0.0.1
::1
# m1.example.com 主机操作
ssh-keygen -t rsa -C m1.example.com
# 免密码登录操作
ssh-copy-id -i ~/.ssh/id_rsa.pub root@m1.example.com
ssh-copy-id -i ~/.ssh/id_rsa.pub root@m2.example.com
# 将 serverA ~/.ssh目录中的 id_rsa.pub 这个文件拷贝到你要登录的 serverB 的~/.ssh目录中
scp ~/.ssh/id_rsa.pub m2.example.com:~/.ssh/
# 然后在 serverB 运行以下命令来将公钥导入到~/.ssh/authorized_keys这个文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在m1和m2中同时执行:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
在m2中使用ssh命令反向访问m1:
ssh m2.example.com
vi /etc/ssh/sshd_config
修改为PubkeyAuthentication yes(如果前面有#,就去掉#)
三、搭建
1.在两台主机创建hadoop文件夹
mkdir -p /hadoop/hdfs/data
mkdir -p /hadoop/hdfs/name
mkdir -p /hadoop/hdfs/tmp
2.环境配置
解压
tar -zxvf hadoop-3.2.0.tar.gz
更名
mv hadoop-3.2.0 hadoop
配置环境变量
echo -e ‘export HADOOP_HOME=/soft/hadoop \n export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin’>>/etc/profile
tar -zxvf jdk-8u201-linux-x64.tar.gz
mv jdk1.8.0_201 jdk1.8
echo -e ‘export JAVA_HOME=/soft/jdk1.8 \n export PATH=$PATH:$JAVA_HOME/bin’>>/etc/profile
source /etc/profile
3.参数配置
运行用户操作,添加如下几句到 /soft/hadoop/etc/hadoop/hadoop-env.sh
vim /soft/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/soft/jdk1.8
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
4.环境变量生效 source /etc/profile
5.hadoop 配置文件
core-site.xml 配置
两个机器配置一致
hdfs-site.xml配置
两个机器配置一致
yarn-site.xml 配置
两个机器配置一致
mapred-site.xml 配置
两个机器配置一致
vim workers 添加如下:
m1机器添加
m1.example.com
m2.example.com
6.格式化name文件夹 hadoop namenode -format
7.在命令行输入start-all.sh启动集群
8.查看datanode健康状态
hdfs dfsadmin -report
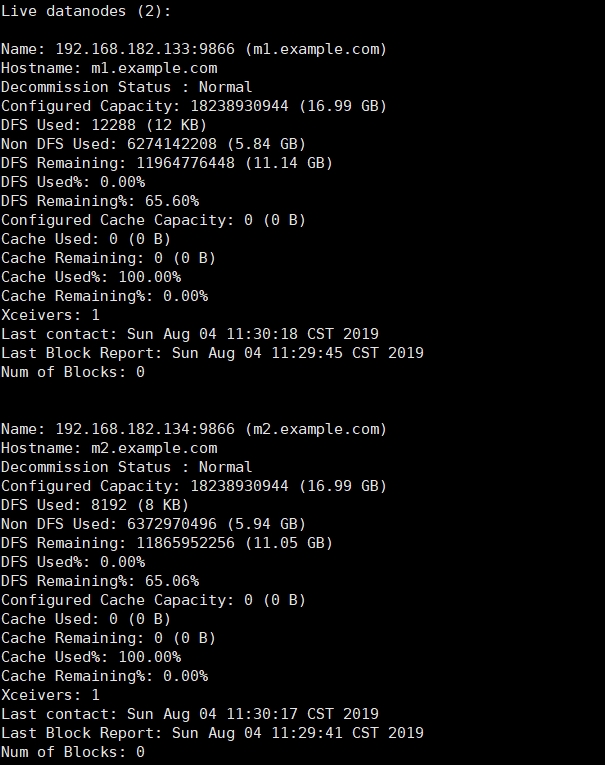
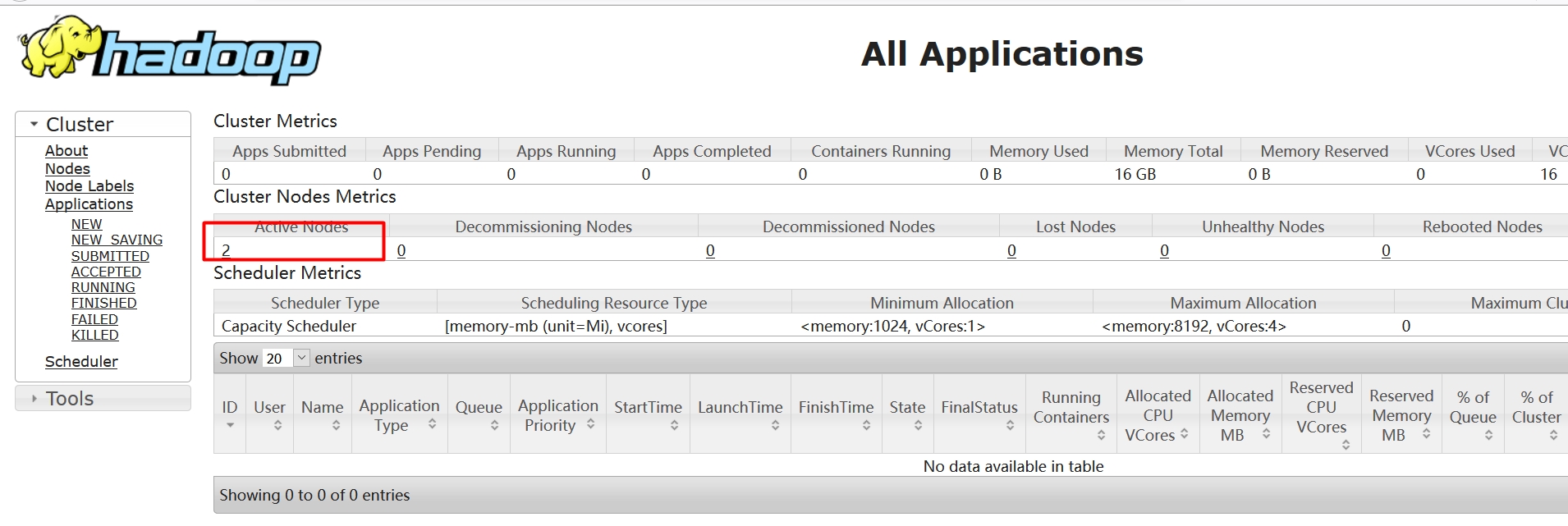
9.查看集群状态
http://m1.example.com:8099/cluster

































还没有评论,来说两句吧...