Hadoop集群搭建
基础环境准备
机器运行环境
3台物理机,Centos7 64bit,2C 8核,16G内存,1TG硬盘
节点配置
集群网络环境集群包含三个节点:节点之间局域网连接,可以相互ping通。节点IP地址和主机名分布如下:
| 192.168.3.198 hdn1 192.168.3.199 hdn2 192.168.3.200 hdn3 |
注意:所有服务安装都以root身份进行,否则会出现很多问题。
修改机器名(所有节点)
修改机器名称
| # hostnamectl set-hostname xxx #hostname // 查看本机名 |
这种方式,可以永久性的修改主机名称。
将HOSTNAME改成机器名称
每个节点机器,都要配置hosts
| # vi /etc/hosts |
内容都改为:
| 192.168.3.198 hdn1 192.168.3.199 hdn2 192.168.3.200 hdn3 |
安装JDK1.8
配置JAVA_HOME环境变量
修改/etc/profile文件配置环境变量, 执行命令:
| # vi /etc/profile |
在profile文件最后,输入下面内容,保存并退出。
export JAVA_HOME=/mnt/hadoop/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
执行下面命令,让配置生效
# source /etc/profile //使修改立即生效
# echo $PATH //查看PATH值
# echo $JAVA_HOME //查看JAVA_HOME值
创建hadoop用户
useradd hadoop
passwd hadoop
使用root用户授权文件
chmod 777 mnt
更改目录权限:chown -R hadoop.hadoop /mnt/hadoop
配置免密登录ssh
1.生成一对秘钥
ssh-keygen -t rsa
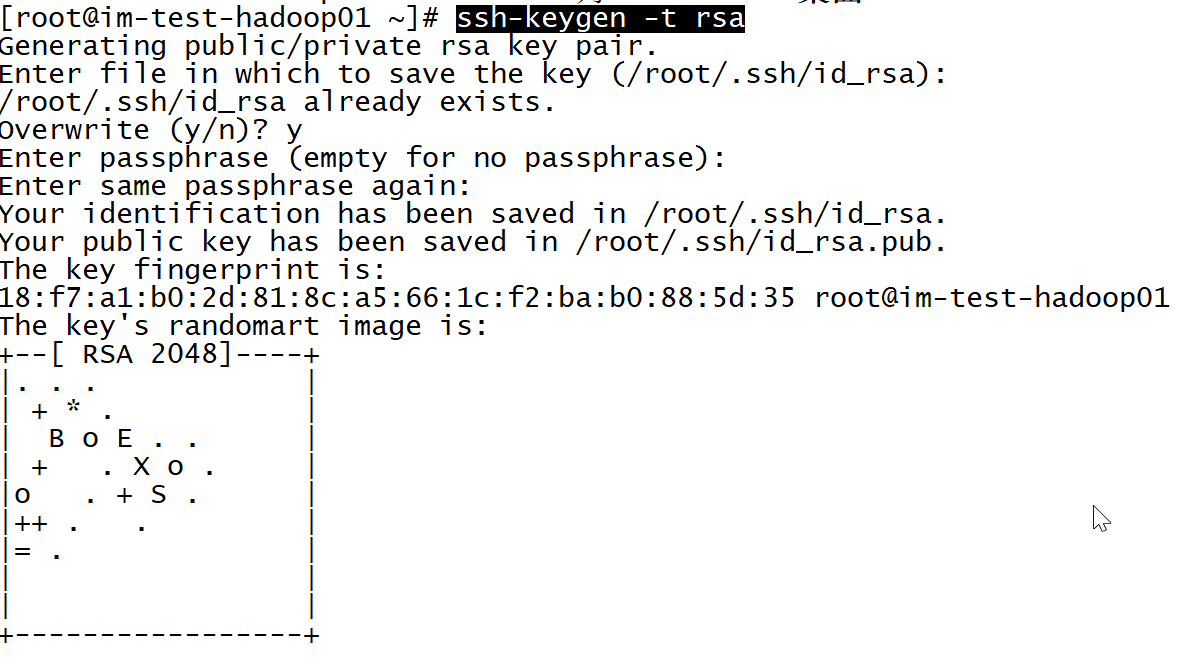
然后cd到 /root/.ssh/目录下,把id_rsa.pub改为authorized_keys
mv id_rsa.pub authorized_keys
把秘钥拷贝到每个节点上
scp authorized_keys id_rsa hadoop@192.168.3.199:/home/hadoop/.ssh
scp authorized_keys id_rsa hadoop@192.168.3.200:/home/hadoop/.ssh
然后执行su - hadoop确认是否可以无密登录
ssh hdn3
ssh hdn2
Hadoop安装
1.解压
tar -zxvf hadoop-2.8.5.tar.gz
2.配置相关文件
1)添加hadoop环境变量
# 修改配置文件
vi /etc/profile
# 在最后下添加
export HADOOP_HOME=/mnt/hadoop/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin
# 刷新配置文件
source /etc/profile
2)修改配置文件
以下配置文件全部位于 /mnt/hadoop/hadoop-2.8.5/etc/hadoop文件夹下
hadoop-env.sh 添加JDK路径
export JAVA_HOME=/mnt/hadoop/jdk1.8.0_181
core-site.xml文件内容:
hdfs-site.xml文件内容:
mapred-site.xml文件内容:
必须先
mv mapred-site.xml.template mapred-site.xml
yarn-site.xml文件内容:
创建masters文件
在198上操作
#touch masters
#vi masters
加入内容:
hdn2
在slaves上添加内容
hdn2
hdn3
在/mnt/hadoop/hadoop-2.8.5 目录下创建三个文件目录 tmp、 name、 data
#mkdir tmp name data
复制到其他主机
用root用户复制/etc/hosts(如果每台机器已经配置,可忽略)
scp /etc/hosts hdn2:/etc/
scp /etc/hosts hdn3:/etc/
复制/etc/profile (记得要刷新环境变量)
scp /etc/profile hdn2:/etc/
scp /etc/profile hdn3:/etc/
用hadoop用户复制/ mnt/hadoop/hadoop-2.8.5
scp -r /mnt/hadoop/hadoop-2.8.5 hdn2:/mnt/hadoop
scp -r /mnt/hadoop/hadoop-2.8.5 hdn3:/mnt/hadoop
记得在slave1和slave2上刷新环境变量
启动:
在master(198)上启动
切换hadoop用户 su - hadoop
第一次启动前格式化
#/mnt/hadoop/hadoop-2.8.5/bin/hdfs namenode -format
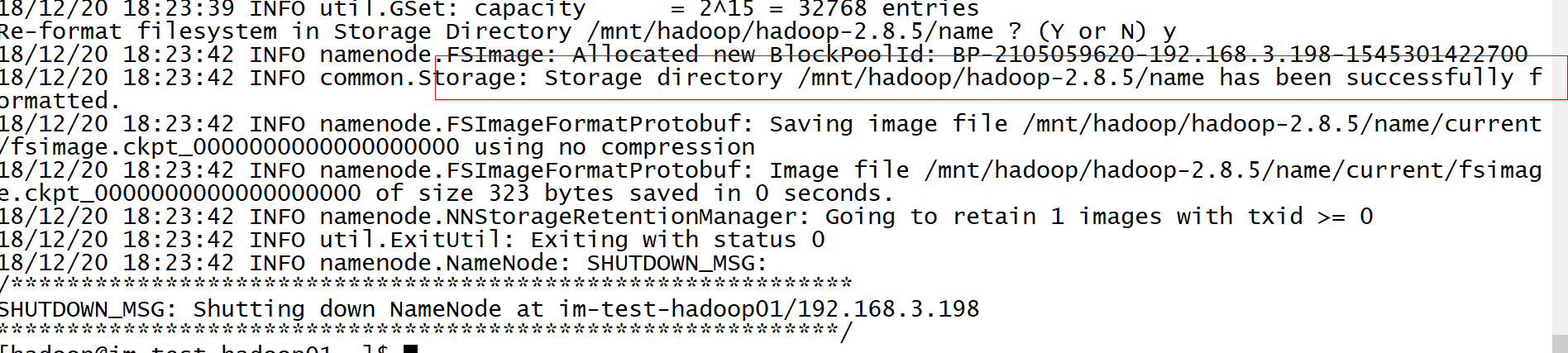
启动dfs
#/mnt/hadoop/hadoop-2.8.5/sbin/start-dfs.sh
启动yarn
#/mnt/hadoop/hadoop-2.8.5/sbin/start-yarn.sh
如果有问题查看日志:
/mnt/hadoop/hadoop-2.8.5/logs
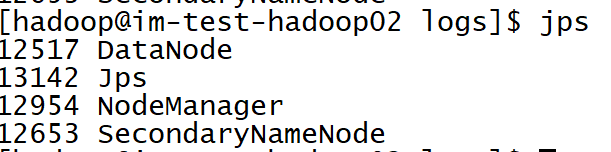
查看:
hdn1(主节点)

hdn2(从节点)
通过浏览器测试yarn:http://192.168.3.198:8088
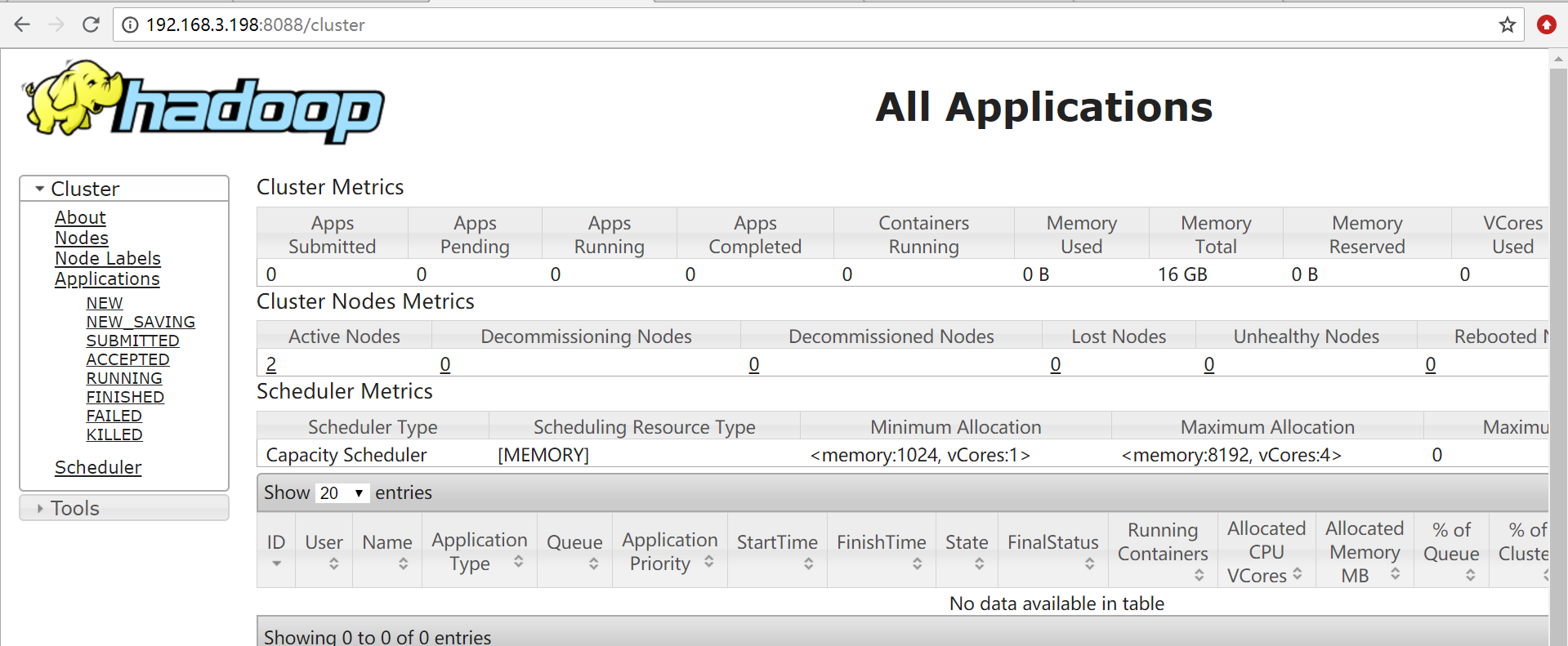
通过浏览器测试hdfs:http://192.168.3.198:50070/
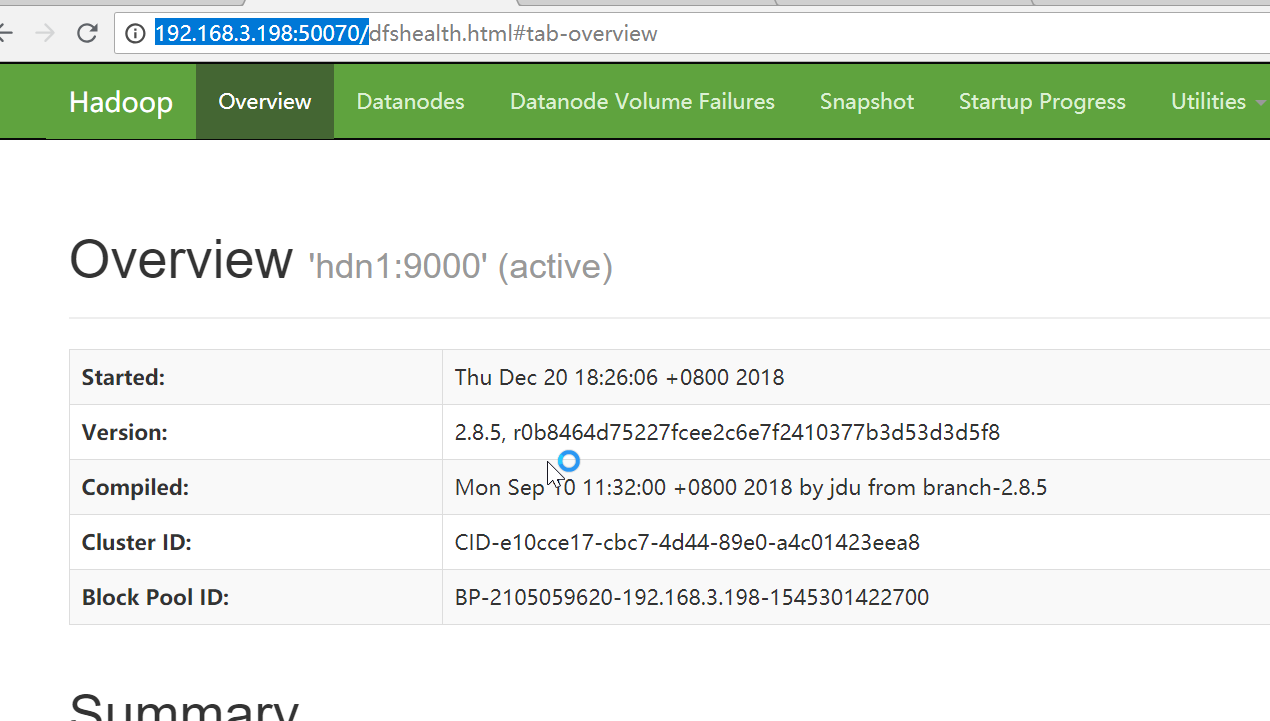
HDFS HA 部署安装
https://blog.csdn.net/w13770269691/article/details/24457241


























![[Leetcode][第889题][JAVA][根据前序和后序遍历构造二叉树][分治][递归]](https://image.dandelioncloud.cn/images/20221123/d21b47c447f743169046f5ea4342b0c6.png "[Leetcode][第889题][JAVA][根据前序和后序遍历构造二叉树][分治][递归]")







还没有评论,来说两句吧...