python爬虫实践----爬取京东图片
爬虫思路:
1.分析url:
http://list.jd.com/list.html?cat=9987,653,655&page=1# url只有page变化,而page代表了页数

下面是根据正则的re库匹配出所需要的dom节点
3.根据匹配出的图片url筛选出图片并下载图片
4.最后通过循环,遍历出所有的页数
完整代码:
import reimport urllib.requestdef craw(url,page):## 读取url地址中的页面html1 = urllib.request.urlopen(url).read();## 读取url的全部信息并转为字符串html1 = str(html1);##匹配元素1---父节点pat1 = '<div id="plist".+? <div class="page clearfix">';result1 = re.compile(pat1).findall(html1);result1 = result1[0];##匹配元素2--子节点pat2='<img width="220" height="220" data-img="1" data-lazy-img="//(.+?\.jpg)">';imagelist=re.compile(pat2).findall(result1);x=1;for imgurl in imagelist:#设置地址跟爬取图片的地址imagename="F:/pythonB/img/"+str(page)+str(x)+".jpg";imgurl= "http://" +imgurl;print(imgurl);try:#保存图片并定义图片名字urllib.request.urlretrieve(imgurl,filename=imagename)except urllib.error.URLError as e:if hasattr(e, "code"):x+=1;if hasattr(e, "reason"):x+=1;x+=1;for i in range(1,79):url = 'http://list.jd.com/list.html?cat=9987,653,655&page='+str(i)craw(url,i);
最后得到所有的图片: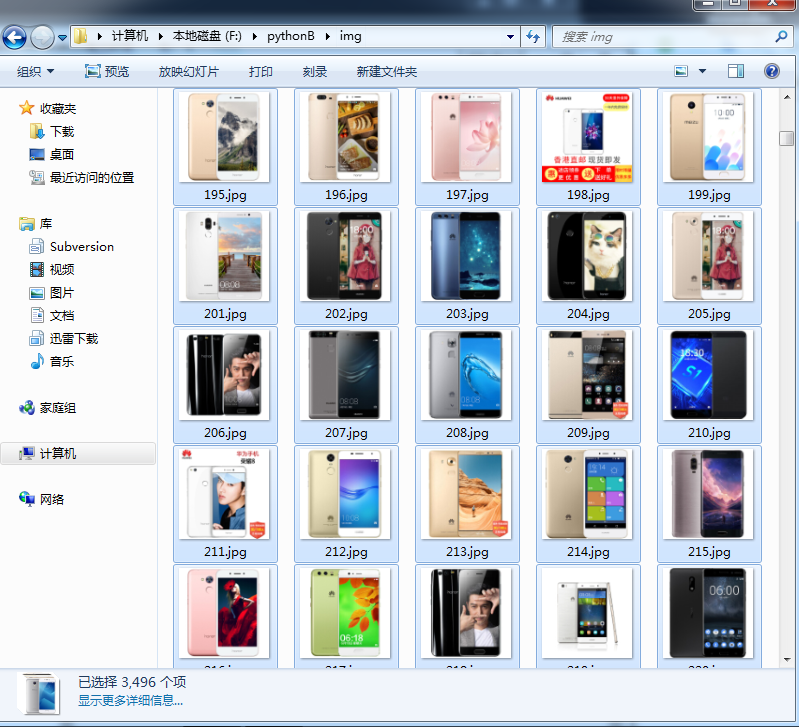


























拓扑排序")

")





还没有评论,来说两句吧...