python爬虫爬取彼岸图网图片
python爬虫爬取彼岸图网图片
话不多说,直接上代码!
import requestsfrom PIL import Imagefrom io import BytesIOimport refrom requests.exceptions import HTTPErrorroot = "http://pic.netbian.com/index_%d.html"uni = "http://pic.netbian.com"AllPage = []AllImgHTML = []AllImgURL = []def GetPageURL(root, Start, counts):if Start == 1:AllPage.append("http://pic.netbian.com/index.html")for i in range(Start + 1, Start + counts):newURL = root.replace("%d", str(i))AllPage.append(newURL)else:for i in range(Start, Start + counts):newURL = root.replace("%d", str(i))AllPage.append(newURL)def GetImgHTML(AllPage):for PageURL in AllPage:try:res = requests.get(PageURL)res.raise_for_status()except HTTPError:print("HTTP Error!")except ConnectionError:print("Failed to connect!")with open("C:/Users/86135/Desktop/PageFile.txt", "w", encoding="ISO-8859-1") as PageFile:PageFile.write(res.text)PageFile.close()with open("C:/Users/86135/Desktop/PageFile.txt", "r", encoding="gbk") as ReadFile:str = ReadFile.read()mid = re.split("\"", str)for i in mid:ImgHTML = re.findall("^/tupian/.*.html$", i)if len(ImgHTML) != 0:AllImgHTML.append(ImgHTML[0])def GetImgURL():UsefulImgHTML = [None for i in range(len(AllImgHTML))]for i in range(len(AllImgHTML)):UsefulImgHTML[i] = uni + AllImgHTML[i]for html in UsefulImgHTML:try:htmlres = requests.get(html)htmlres.raise_for_status()except HTTPError:print("HTTP Error!")except ConnectionError:print("Failed to connect!")with open("C:/Users/86135/Desktop/ImgHTML.txt", "w", encoding="ISO-8859-1") as ImgHTML:ImgHTML.write(htmlres.text)ImgHTML.close()with open("C:/Users/86135/Desktop/ImgHTML.txt", "r", encoding="gbk") as ReadHTML:str = ReadHTML.read()mid = re.split("\"", str)for i in mid:ImgURL = re.search("^/uploads/allimg/.*.jpg$", i)if ImgURL is not None:AllImgURL.append(ImgURL[0])breakUsefulImgURL = [None for i in range(len(AllImgURL))]for i in range(len(AllImgURL)):UsefulImgURL[i] = uni + AllImgURL[i]return UsefulImgURLdef DownloadWallpaper(url, path):try:res = requests.get(url)res.raise_for_status()MyImage = Image.open(BytesIO(res.content))MyImage.save(path)print("Done...")except HTTPError:print("HTTP Error!")except ConnectionError:print("Failed to connect!")if __name__ == "__main__":GetPageURL(root, 2, 2)GetImgHTML(AllPage)UsefulImgURL = GetImgURL()num = []for i in range(len(UsefulImgURL)):num.append(i)UsefulSavePath = [None for i in range(len(UsefulImgURL))]for i in range(len(UsefulSavePath)):UsefulSavePath[i] = "C:/Users/86135/Desktop/" + str(num[i]) + ".jpg"for i in range(len(UsefulImgURL)):print(i, end=" ")DownloadWallpaper(UsefulImgURL[i], UsefulSavePath[i])print("Task completed!")
运行结果如下: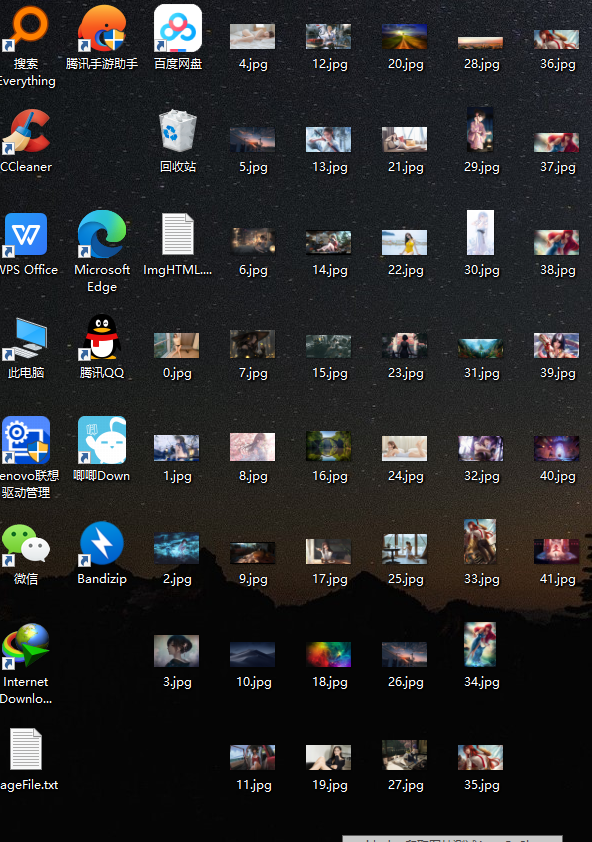





























")




还没有评论,来说两句吧...