写一篇最好懂的lucene讲解
Directory directory = FSDirectory.open(new File(“d:\\indexDir”));这行代码报错?
解决方案:
问题的缘由就是Lucene版本不兼容,下面的FSDirectory.open()在Lucene5.0.0版本下,open的参数是Path而不是File。
String path = " ... ";directory = FSDirectory.open(new File(path));
所以在Lucene5.0.0版本下,正确的打开方式如下,这样得到的就是File,然后能正常赋给directory了。
String path = " ... ";directory = FSDirectory.open(Paths.get(path));
maven依赖:
<apache.lucene>5.5.5</apache.lucene><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-smartcn</artifactId><version>${apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>${apache.lucene}</version></dependency>
Lucene之索引查看工具Luke-yellowcong
http://www.getopt.org/luke/
DmitryKey/luke
开启:
java -jar lukeall-0.9.9.jar / 双击
代码实现:
package com.mtons.mblog.modules.service.impl;import com.mtons.mblog.BootApplication;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.*;import org.apache.lucene.search.*;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.test.context.junit4.SpringRunner;import java.nio.file.Paths;import java.util.ArrayList;import java.util.Collection;@RunWith(SpringRunner.class)@SpringBootTest(classes = BootApplication.class)public class PostSearchInfoTest {@AutowiredPostServiceImpl postService;@Testpublic void cleanPostPic() {}// 创建索引@Testpublic void testCreate() throws Exception{//1 创建文档对象Document document = new Document();// 创建并添加字段信息。参数:字段的名称、字段的值、是否存储,这里选Store.YES代表存储到文档列表。Store.NO代表不存储document.add(new StringField("id", "1", Field.Store.YES));// 这里我们title字段需要用TextField,即创建索引又会被分词。StringField会创建索引,但是不会被分词document.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));//2 索引目录类,指定索引在硬盘中的位置String path = "d:\\indexDir";//Directory directory = FSDirectory.open(new File("d:\\indexDir"));Directory directory = FSDirectory.open(Paths.get(path));//3 创建分词器对象Analyzer analyzer = new StandardAnalyzer();//4 索引写出工具的配置对象IndexWriterConfig conf = new IndexWriterConfig(analyzer);//5 创建索引的写出工具类。参数:索引的目录和配置信息IndexWriter indexWriter = new IndexWriter(directory, conf);//6 把文档交给IndexWriterindexWriter.addDocument(document);//7 提交indexWriter.commit();//8 关闭indexWriter.close();}// 批量创建索引@Testpublic void testCreate2() throws Exception{// 创建文档的集合Collection<Document> docs = new ArrayList<>();// 创建文档对象Document document1 = new Document();document1.add(new StringField("id", "1", Field.Store.YES));document1.add(new TextField("title", "liyunfeng", Field.Store.YES));docs.add(document1);// 创建文档对象Document document2 = new Document();document2.add(new StringField("id", "2", Field.Store.YES));document2.add(new TextField("title", "谷歌地图之父加盟FaceBook", Field.Store.YES));docs.add(document2);// 创建文档对象Document document3 = new Document();document3.add(new StringField("id", "3", Field.Store.YES));document3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES));docs.add(document3);// 创建文档对象Document document4 = new Document();document4.add(new StringField("id", "4", Field.Store.YES));document4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES));docs.add(document4);// 创建文档对象Document document5 = new Document();document5.add(new StringField("id", "5", Field.Store.YES));document5.add(new TextField("title", "谷歌地图之父拉斯加盟社交网站Facebook", Field.Store.YES));docs.add(document5);// 索引目录类,指定索引在硬盘中的位置String path = "d:\\indexDir";//Directory directory = FSDirectory.open(new File("d:\\indexDir"));Directory directory = FSDirectory.open(Paths.get(path));// 引入IK分词器Analyzer analyzer = new StandardAnalyzer();// 索引写出工具的配置对象IndexWriterConfig conf = new IndexWriterConfig(analyzer);// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);// 创建索引的写出工具类。参数:索引的目录和配置信息IndexWriter indexWriter = new IndexWriter(directory, conf);// 把文档集合交给IndexWriterindexWriter.addDocuments(docs);// 提交indexWriter.commit();// 关闭indexWriter.close();}public void search(Query query) throws Exception {// 索引目录对象String path = "D:\\indexDir";//Directory directory = FSDirectory.open(new File("d:\\indexDir"));Directory directory = FSDirectory.open(Paths.get(path));// 索引读取工具IndexReader reader = DirectoryReader.open(directory);// 索引搜索工具IndexSearcher searcher = new IndexSearcher(reader);// 搜索数据,两个参数:查询条件对象要查询的最大结果条数// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。TopDocs topDocs = searcher.search(query, 10);// 获取总条数System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {// 取出文档编号int docID = scoreDoc.doc;// 根据编号去找文档Document doc = reader.document(docID);System.out.println("id: " + doc.get("id"));System.out.println("title: " + doc.get("title"));// 取出文档得分System.out.println("得分: " + scoreDoc.score);}}/** 测试普通词条查询* 注意:Term(词条)是搜索的最小单位,不可再分词。值必须是字符串!*/@Testpublic void testTermQuery() throws Exception {// 创建词条查询对象Query query = new TermQuery(new Term("title", "谷歌地图"));search(query);}/** 测试通配符查询* ? 可以代表任意一个字符* * 可以任意多个任意字符*/@Testpublic void testWildCardQuery() throws Exception {// 创建查询对象Query query = new WildcardQuery(new Term("title", "*liyunfeng*"));search(query);}/** 测试:数值范围查询* 注意:数值范围查询,可以用来对非String类型的ID进行精确的查找*/@Testpublic void testNumericRangeQuery() throws Exception{// 数值范围查询对象,参数:字段名称,最小值、最大值、是否包含最小值、是否包含最大值Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);search(query);}/** 布尔查询:* 布尔查询本身没有查询条件,可以把其它查询通过逻辑运算进行组合!* 交集:Occur.MUST + Occur.MUST* 并集:Occur.SHOULD + Occur.SHOULD* 非:Occur.MUST_NOT*/@Testpublic void testBooleanQuery() throws Exception{Query query1 = NumericRangeQuery.newLongRange("id", 1L, 3L, true, true);Query query2 = NumericRangeQuery.newLongRange("id", 2L, 4L, true, true);// 创建布尔查询的对象BooleanQuery query = new BooleanQuery();// 组合其它查询query.add(query1, BooleanClause.Occur.MUST_NOT);query.add(query2, BooleanClause.Occur.SHOULD);search(query);}/** 测试模糊查询*/@Testpublic void testFuzzyQuery() throws Exception {// 创建模糊查询对象:允许用户输错。但是要求错误的最大编辑距离不能超过2// 编辑距离:一个单词到另一个单词最少要修改的次数 facebool --> facebook 需要编辑1次,编辑距离就是1// Query query = new FuzzyQuery(new Term("title","fscevool"));// 可以手动指定编辑距离,但是参数必须在0~2之间Query query = new FuzzyQuery(new Term("title","谷歌地图之父跳槽faceboog"),1);search(query);}@Testpublic void testUpdate() throws Exception{// 创建目录对象String path = "D:\\indexDir";//Directory directory = FSDirectory.open(new File("d:\\indexDir"));Directory directory = FSDirectory.open(Paths.get(path));// 创建配置对象Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig conf = new IndexWriterConfig(analyzer);// 创建索引写出工具IndexWriter writer = new IndexWriter(directory, conf);// 创建新的文档数据Document doc = new Document();doc.add(new StringField("id","1", Field.Store.YES));doc.add(new TextField("title","谷歌地图之父跳槽facebook ", Field.Store.YES));/* 修改索引。参数:* 词条:根据这个词条匹配到的所有文档都会被修改* 文档信息:要修改的新的文档数据*/writer.updateDocument(new Term("id","1"), doc);// 提交writer.commit();// 关闭writer.close();}/** 演示:删除索引* 注意:* 一般,为了进行精确删除,我们会根据唯一字段来删除。比如ID* 如果是用Term删除,要求ID也必须是字符串类型!*/@Testpublic void testDelete() throws Exception {// 创建目录对象String path = "D:\\indexDir";//Directory directory = FSDirectory.open(new File("d:\\indexDir"));Directory directory = FSDirectory.open(Paths.get(path));// 创建配置对象Analyzer analyzer = new StandardAnalyzer();// 索引写出工具的配置对象IndexWriterConfig conf = new IndexWriterConfig(analyzer);// 创建索引写出工具IndexWriter writer = new IndexWriter(directory, conf);// 根据词条进行删除// writer.deleteDocuments(new Term("id", "1"));// 根据query对象删除,如果ID是数值类型,那么我们可以用数值范围查询锁定一个具体的ID// Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);// writer.deleteDocuments(query);// 删除所有writer.deleteAll();// 提交writer.commit();// 关闭writer.close();}}
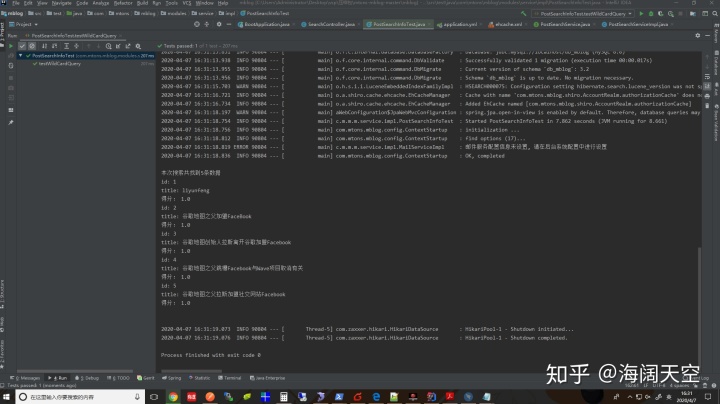
输出:

























![Tp6 报错:Driver [Think] not supported.](https://image.dandelioncloud.cn/dist/img/NoSlightly.png "Tp6 报错:Driver [Think] not supported.")


还没有评论,来说两句吧...