不止是CSS偏移反爬虫
文章目录
- CSS偏移反爬虫
- 案例分析
- 代码说明
- 效果展示
- 关注不迷路哦
CSS偏移反爬虫
CSS偏移反爬虫指的是利用CSS样式将乱序的文字排本为人类正常阅读顺序的行为。这个概念不是很好理解,我们可以通过对比两端文字来加深对这个概念的理解。
- HTML文本中的文字:我的学号是 1308205,我在北京大学读书。
- 浏览器显示的文字:我的学号是 1380205,我在北京大学读书。
案例分析
爬虫取到的学号是1308205,但用户在浏览器中看到的却是1380205.如果不细心观察,爬虫工程师很容易被爬取结果糊弄。这种混淆方法和图片伪装一样,是不会影响用户阅读的。让人好奇的是,浏览器如何将HTML文本中的数字按照开发者的意愿排序或放置呢?这种放置规则是如何运行的呢?我们可以通过一个具体的例子来了解CSS偏移反爬虫的应用和绕过方法。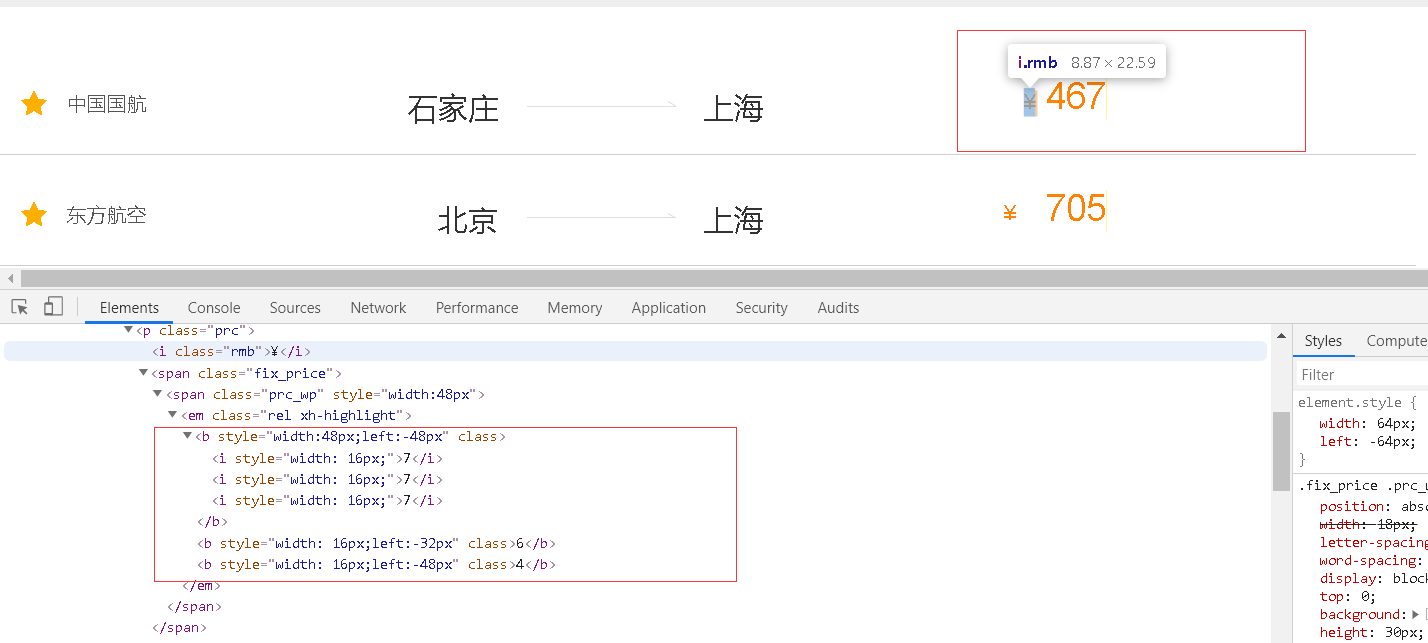
代码说明
"""示例:CSS偏移反爬虫示例网址:http://www.porters.vip/confusion/flight.html任务:爬取航班查询和机票销售网站页面中的航站名称,所属航空公司和票价。"""import requestsimport refrom parsel import Selectorclass Css(object):def __init__(self):self.url = 'http://www.porters.vip/confusion/flight.html'self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}def get_response_from_page(self, url):response = requests.get(url, headers=self.headers)if response.status_code == 200:return responseelse:return Falsedef get_contnet_from_page(self):response = self.get_response_from_page(self.url).textsel = Selector(response)em = sel.css('em.rel').extract()for element in em:element = Selector(element)#定位所以的<b>标签element_b = element.css('b').extract()# print(element_b)bl = Selector(element_b.pop(0))base_price = bl.css('i::text').extract()print(base_price)alternate_price = []for eb in element_b:eb = Selector(eb)#提取<b>标签的style属性style = eb.css('b::attr("style")').get()#获得具体的位置position = ''.join(re.findall(r'left:(.*?)px',style))#获取该标签下的数字value = eb.css('b::text').get()#将<b>标签的位置信息和数字以字典的格式添加到替补票价列表中alternate_price.append({'position':position,'value':value})for al in alternate_price:position = int(al.get('position'))value = al.get('value')#判断位置的数值是否正整数puls = True if position >= 0 else False#计算下标,以16px为基准index = int(position / 16)#替换第一对<b>标签值列表中的元素,也就是完整值覆盖操作base_price[index] = valueprint(base_price)if __name__ == '__main__':css = Css()css.get_contnet_from_page()
效果展示
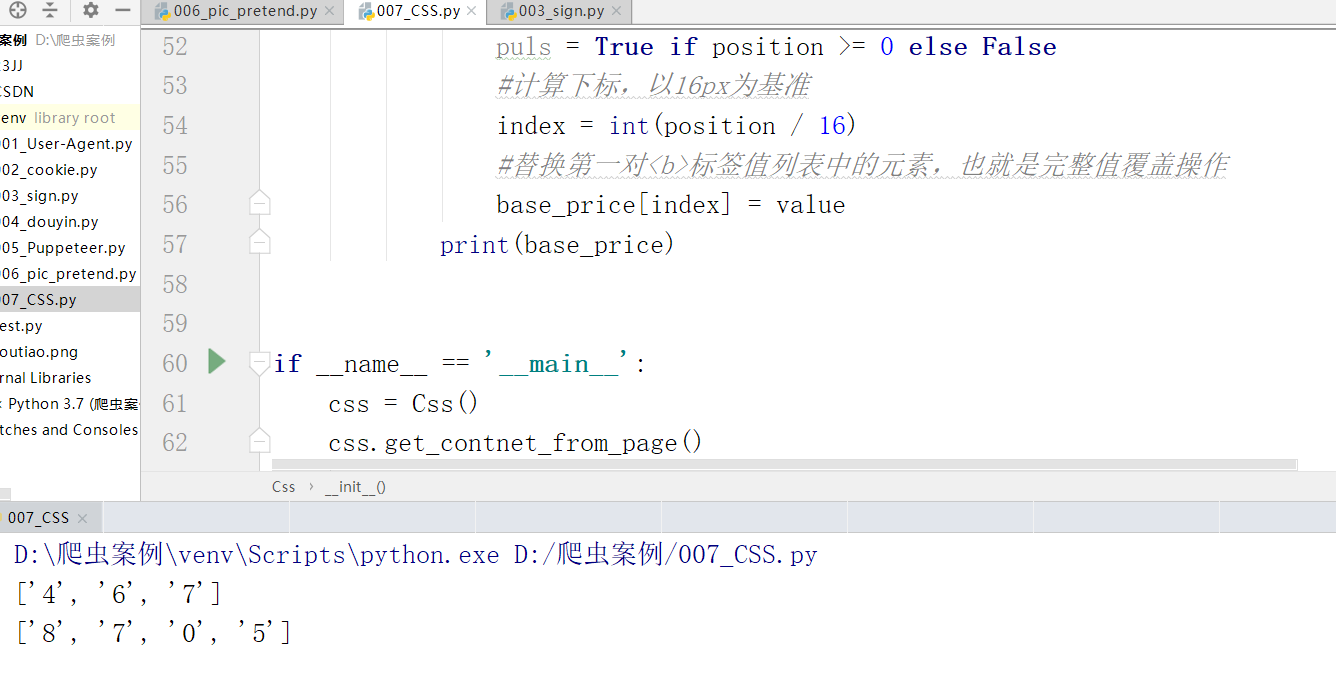
关注不迷路哦



























. fatal: Could not read from remote repository")







还没有评论,来说两句吧...