gensim实现word2vec
word2vec模型
假设给定一个长度为T的文本序列,设时间步t的词为w(t)。假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为m时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率:
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) \prod_{t=1}^{T} \prod_{-m \leq j \leq m, j \neq 0} P\left(w^{(t+j)} | w^{(t)}\right) ∏t=1T∏−m≤j≤m,j=0P(w(t+j)∣w(t))
设中心词wc在词典中索引为c,背景词wo在词典中索引为o,给定中心词生成背景词的条件概率可以通过对向量内积做softmax运算而得到:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) P\left(w_{o} | w_{c}\right)=\frac{\exp \left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\boldsymbol{u}_{i}^{\top} \boldsymbol{v}_{c}\right)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)
模型训练
通过最大化似然函数来学习模型参数,即最大似然估计。这等价于最小化以下损失函数:
− ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w ( t + j ) ∣ w ( t ) ) -\sum_{t=1}^{T} \sum_{-m \leq j \leq m, j \neq 0} \log P\left(w^{(t+j)} | w^{(t)}\right) −∑t=1T∑−m≤j≤m,j=0logP(w(t+j)∣w(t))
采用随机梯度下降算法
∂ log P ( w o ∣ w c ) ∂ v c = u o − ∑ j ∈ V exp ( u j ⊤ v c ) u j ∑ i ∈ V exp ( u i ⊤ v c ) = u o − ∑ j ∈ V ( exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) ) u j = u o − ∑ j ∈ V P ( w j ∣ w c ) u j \begin{aligned} \frac{\partial \log P\left(w_{o} | w_{c}\right)}{\partial \boldsymbol{v}_{c}} &=\boldsymbol{u}_{o}-\frac{\sum_{j \in \mathcal{V}} \exp \left(\boldsymbol{u}_{j}^{\top} \boldsymbol{v}_{c}\right) \boldsymbol{u}_{j}}{\sum_{i \in \mathcal{V}} \exp \left(\boldsymbol{u}_{i}^{\top} \boldsymbol{v}_{c}\right)} \\ &=\boldsymbol{u}_{o}-\sum_{j \in \mathcal{V}}\left(\frac{\exp \left(\boldsymbol{u}_{j}^{\top} \boldsymbol{v}_{c}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\boldsymbol{u}_{i}^{\top} \boldsymbol{v}_{c}\right)}\right) \boldsymbol{u}_{j} \\ &=\boldsymbol{u}_{o}-\sum_{j \in \mathcal{V}} P\left(w_{j} | w_{c}\right) \boldsymbol{u}_{j} \end{aligned} ∂vc∂logP(wo∣wc)=uo−∑i∈Vexp(ui⊤vc)∑j∈Vexp(uj⊤vc)uj=uo−j∈V∑(∑i∈Vexp(ui⊤vc)exp(uj⊤vc))uj=uo−j∈V∑P(wj∣wc)uj
Gensim词向量训练
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
1.维基百科数据集(大约1.8G)
https://dumps.wikimedia.org/zhwiki/20190701/
2.将wiki的xml文件处理成正常的txt文件

代码:
#把基百科的下载xml.bz2文件转化成text文件 (process.py)import loggingimport os.pathimport sysfrom gensim.corpora import WikiCorpusif __name__ == '__main__':program = os.path.basename(sys.argv[0])logger = logging.getLogger(program)logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')logging.root.setLevel(level=logging.INFO)logger.info("running %s" % ' '.join(sys.argv))# check and process input argumentsif len(sys.argv) < 3:print(globals()['__doc__'] % locals())sys.exit(1)inp, outp = sys.argv[1:3]space =' 'i = 0output = open(outp, 'w',encoding='utf-8')wiki = WikiCorpus(inp, lemmatize=False, dictionary={ })for text in wiki.get_texts():s = space.join(text)s = s.encode('utf-8').decode('utf8') + "\n"output.write(s)i = i + 1if (i % 10000 == 0):logger.info("Saved " + str(i) + " articles")output.close()logger.info("Finished Saved " + str(i) + " articles")
运行:

3.使用opencc将繁体txt转换为简体txt

将前面生成的wiki.zh.text拖动至opencc-1.0.1-win64文件夹中,cmd在当前文件夹中输入如下:
opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json
4.jieba分词
代码:
#jieba分词(jieba_cut.py)import jiebaimport jieba.analyseimport jieba.posseg as psegimport codecs, sysdef cut_words(sentence):#print sentencereturn " ".join(jieba.cut(sentence)).encode('utf-8')f = codecs.open('wiki.zh.jian.text', 'r', encoding="utf8")target = codecs.open("zh.jian.wiki.seg.txt", 'w', encoding="utf8")print('open files')line_num = 1line = f.readline()while line:print('---- processing ', line_num, ' article----------------')line_seg = " ".join(jieba.cut(line))target.writelines(line_seg)line_num = line_num + 1line = f.readline()f.close()target.close()exit()
5.词向量训练
from __future__ import print_functionimport loggingimport osimport sysimport multiprocessingfrom gensim.models import Word2Vecfrom gensim.models.word2vec import LineSentenceif __name__ == '__main__':program = os.path.basename(sys.argv[0])logger = logging.getLogger(program)logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')logging.root.setLevel(level=logging.INFO)logger.info("running %s" % ' '.join(sys.argv))# check and process input argumentsif len(sys.argv) < 4:print("Useing: python train_word2vec_model.py input_text ""output_gensim_model output_word_vector")sys.exit(1)inp, outp1, outp2 = sys.argv[1:4]model = Word2Vec(LineSentence(inp), size=200, window=5, min_count=5,workers=multiprocessing.cpu_count())model.save(outp1)model.wv.save_word2vec_format(outp2, binary=False)
训练过程大致为25分钟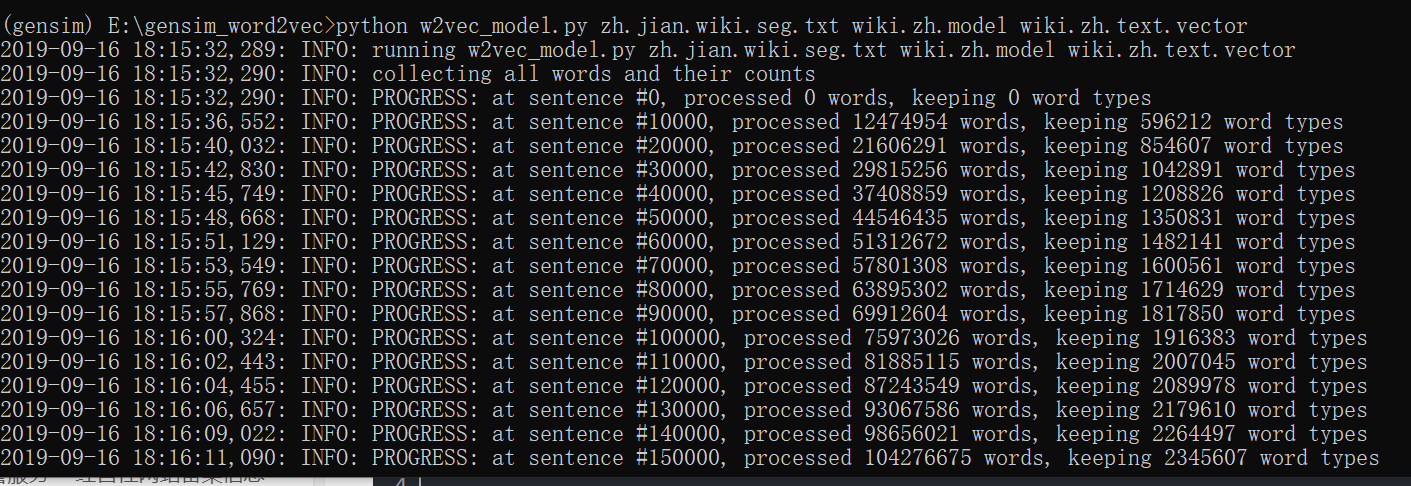
训练后得到的词向量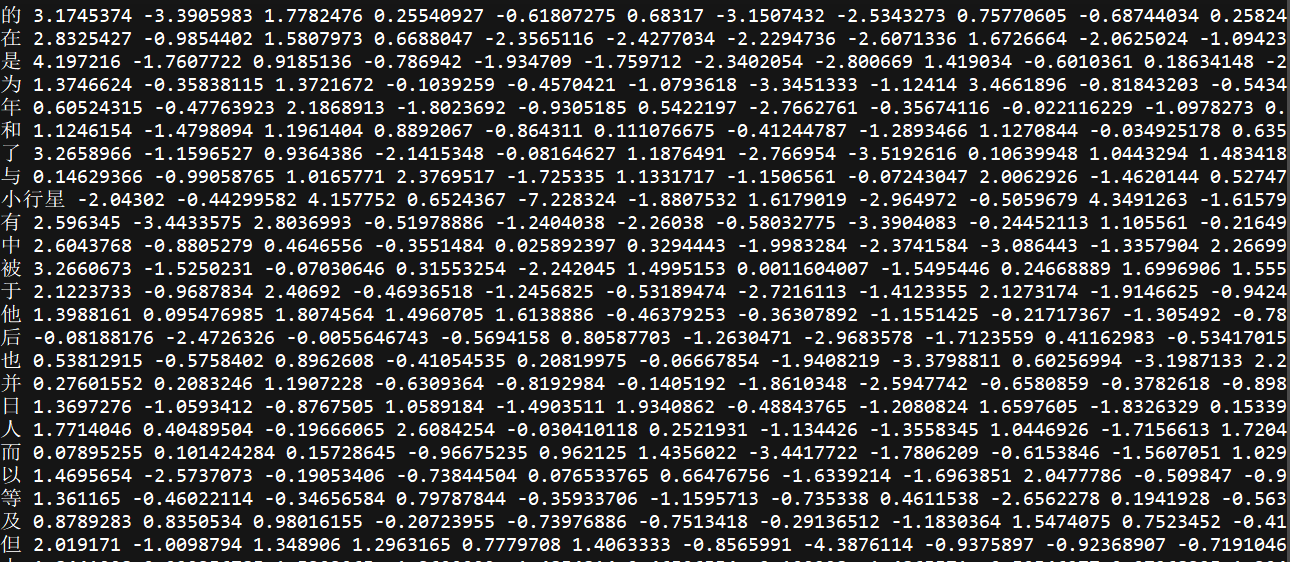
6.测试模型
查找相似词
from gensim.models import Word2Vecen_wiki_word2vec_model=Word2Vec.load('wiki.zh.model')testwords=['孩子','苹果','篮球','学习','动物']for i in range (5):res = en_wiki_word2vec_model.wv.most_similar(testwords[i])print (testwords[i])print (res)
结果: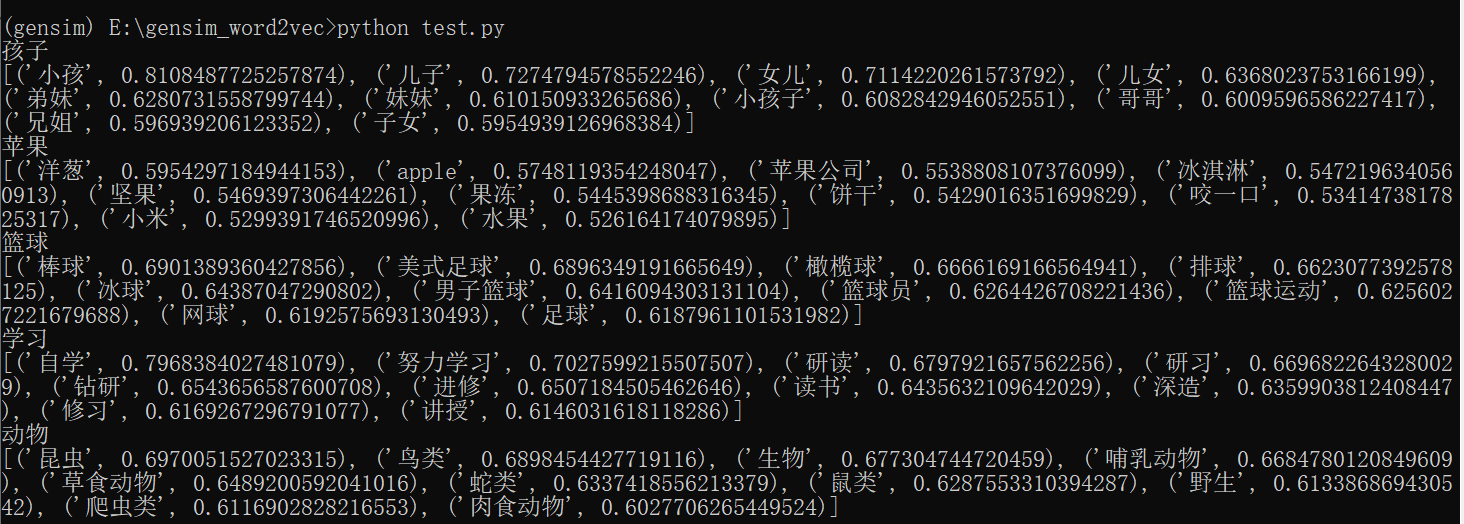




























")




还没有评论,来说两句吧...