FairMOT中的deque怎么存ReID特征的?
1.FairMOT代码逻辑分析
个人理解根据相关代码逻辑连起来,在下面做了注释。
# opts.py# 这里是track_buffer参数默认值self.parser.add_argument('--track_buffer', type=int, default=30, help='tracking buffer')# multitracker.py# 在这里有两个类的实现,JDETracker类里初始化了一个STrack类型的列表,这个过程中会初始化保存特征的deque,设置deque大小。from collections import dequeclass JDETracker(object):self.features = deque([], maxlen=buffer_size)def update(self, im_blob, img0):if len(dets) > 0:'''Detections'''detections = [STrack(STrack.tlbr_to_tlwh(tlbrs[:4]), tlbrs[4], f, 30) for(tlbrs, f) in zip(dets[:, :5], id_feature)]else:detections = []...output_stracks = [track for track in self.tracked_stracks if track.is_activated]# 输出每一个ID的特征长度,即特征的个数,主要是如果某帧里面出现了某个ID,就会将其他特征append到deque中,当超过长度阈值的时候,就会把先进deque中的特征删除,将新特征加到队尾(先进先出)。print("detections feature : {}".format([len(i.features) for i in output_stracks]))# 在STrack中还包含更新特征class STrack(BaseTrack):self.buffer_size = int(frame_rate / 30.0 * opt.track_buffer)def update_features(self, feat):feat /= np.linalg.norm(feat)self.curr_feat = featsif self.smooth_feat is None:self.smooth_feat = featelse:self.smooth_feat = self.alpha * self.smooth_feat + (1 - self.alpha) * featself.features.append(feat)self.smooth_feat /= np.linalg.norm(self.smooth_feat)
2.collections deque进出demo
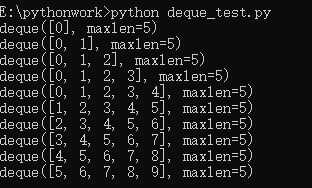
下面是写的一个测试小demo。由于feature维度大了,所以直接打印输出也不太好看清,代码中是怎么对存在队列中的特征怎么处理的。所以写了这样一个demo。目的是当append的元素个数超出初始化队列范围,怎么处理的?
# deque_test.pyfrom collections import dequedef main():features = deque([], maxlen=5)for i in range(10):features.append(i)print(features)main()
运行显示:
3.总结
根据1.2,可以发现,当每个ID特征个数超过buffer_size时,会用新特征代替之前的特征,放到deque中。
说一下里面的几种情况吧:
(1) 当激活的Track,一直处于激活态,那么deque中对应ID的特征会一直更新,未超出buffer_size时,就不断加1,当超出时,就删除最早的特征,添加当前ID特征;
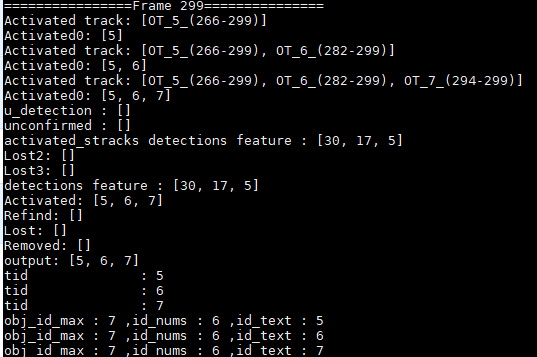
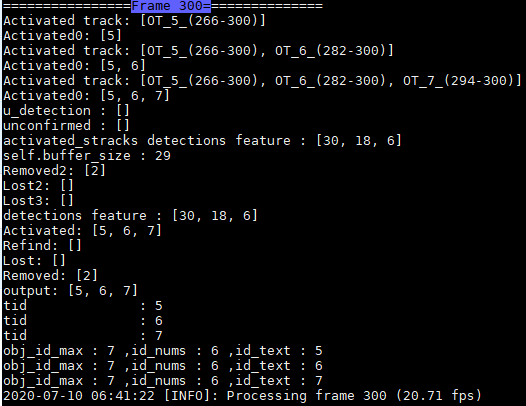
注:这两帧完美诠释了是否超出buffer_size的操作。ID=6,7未超过buffer_size,特征个数加1,ID=5超出了buffer_size,所以特征个数不变,但是特征都在更新。
(2)当激活的Track丢失后,会将其ID特征放到lost_stracks里,如果refind了话,会将lost_stracks中的特征在放到activated_stracks中。
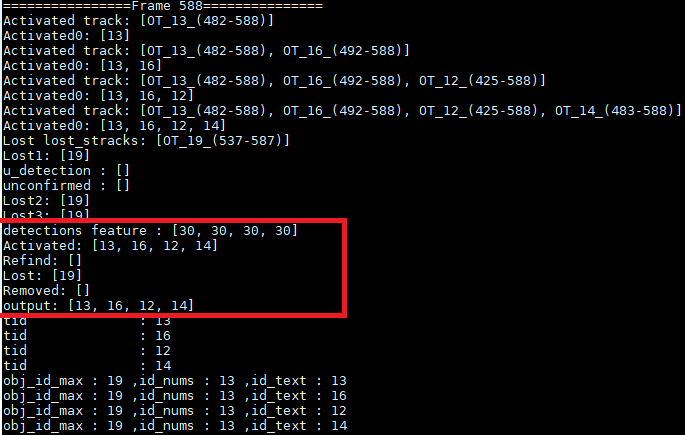
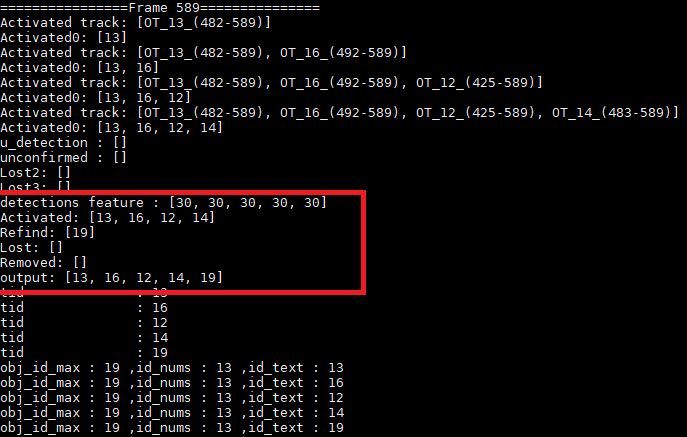
注:由上图可以看到Frame588帧时,ID=19丢失,detection feature也只有4个ID的了,Frame589找回了ID19,detection feature有5个ID的了。
之前有人私信我问这部分的的注释代码,现在将其贴出来:
FairMOT/src/lib/multitracker.py目录下的函数:
def update(self, im_blob, img0):self.frame_id += 1print('================Frame {}==============='.format(self.frame_id))activated_stracks = []refind_stracks = []lost_stracks = []removed_stracks = []width = img0.shape[1]height = img0.shape[0]inp_height = im_blob.shape[2]inp_width = im_blob.shape[3]c = np.array([width / 2., height / 2.], dtype=np.float32)s = max(float(inp_width) / float(inp_height) * height, width) * 1.0meta = {'c': c, 's': s,'out_height': inp_height // self.opt.down_ratio,'out_width': inp_width // self.opt.down_ratio}''' Step 1: Network forward, get detections & embeddings'''with torch.no_grad():output = self.model(im_blob)[-1]# heatmap and width/height ReID_featurehm = output['hm'].sigmoid_()wh = output['wh']id_feature = output['id']id_feature = F.normalize(id_feature, dim=1)reg = output['reg'] if self.opt.reg_offset else None# decode by heatmap and width/height and get coordinatedets, inds = mot_decode(hm, wh, reg=reg, cat_spec_wh=self.opt.cat_spec_wh, K=self.opt.K)id_feature = _tranpose_and_gather_feat(id_feature, inds)id_feature = id_feature.squeeze(0)id_feature = id_feature.cpu().numpy()dets = self.post_process(dets, meta)dets = self.merge_outputs([dets])[1]# filter the dets which score is lower than self.opt.conf_thresremain_inds = dets[:, 4] > self.opt.conf_thresdets = dets[remain_inds]id_feature = id_feature[remain_inds]print("id_feature shape : {}".format(id_feature.shape))# vis'''for i in range(0, dets.shape[0]):bbox = dets[i][0:4]cv2.rectangle(img0, (bbox[0], bbox[1]),(bbox[2], bbox[3]),(0, 255, 0), 2)cv2.imshow('dets', img0)cv2.waitKey(0)id0 = id0-1'''# building connections between detection and id featureif len(dets) > 0:'''Detections'''detections = [STrack(STrack.tlbr_to_tlwh(tlbrs[:4]), tlbrs[4], f, 30) for(tlbrs, f) in zip(dets[:, :5], id_feature)]else:detections = []''' Add newly detected tracklets to tracked_stracks'''unconfirmed = []tracked_stracks = [] # type: list[STrack]for track in self.tracked_stracks:if not track.is_activated:unconfirmed.append(track)else:tracked_stracks.append(track)''' Step 2: First association, with embedding'''strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)# Predict the current location with KF#for strack in strack_pool:#strack.predict()STrack.multi_predict(strack_pool)dists = matching.embedding_distance(strack_pool, detections)#dists = matching.gate_cost_matrix(self.kalman_filter, dists, strack_pool, detections)# 运动估计dists = matching.fuse_motion(self.kalman_filter, dists, strack_pool, detections)matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.7)for itracked, idet in matches:track = strack_pool[itracked]det = detections[idet]if track.state == TrackState.Tracked:track.update(detections[idet], self.frame_id)activated_stracks.append(track)print('Activated track: {}'.format([track for track in activated_stracks]))print('Activated0: {}'.format([track.track_id for track in activated_stracks]))else:track.re_activate(det, self.frame_id, new_id=False)refind_stracks.append(track)''' Step 3: Second association, with IOU'''detections = [detections[i] for i in u_detection]r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]dists = matching.iou_distance(r_tracked_stracks, detections)# matches for Detection and Track match,# u_track for track can't find detection which is in current picture,# u_detection for detection can't find track at before track list,matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.5)for itracked, idet in matches:track = r_tracked_stracks[itracked]det = detections[idet]if track.state == TrackState.Tracked:track.update(det, self.frame_id)activated_stracks.append(track)print('Activated1: {}'.format([track for track in activated_stracks]))else:track.re_activate(det, self.frame_id, new_id=False)refind_stracks.append(track)for it in u_track:track = r_tracked_stracks[it]if not track.state == TrackState.Lost:track.mark_lost()lost_stracks.append(track)print('Lost lost_stracks: {}'.format([track for track in lost_stracks]))print('Lost1: {}'.format([track.track_id for track in lost_stracks]))'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''detections = [detections[i] for i in u_detection]dists = matching.iou_distance(unconfirmed, detections)print('u_detection : {}'.format([i for i in u_detection]))print('unconfirmed : {}'.format([i for i in unconfirmed]))matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)for itracked, idet in matches:unconfirmed[itracked].update(detections[idet], self.frame_id)activated_stracks.append(unconfirmed[itracked])print('Activated2: {}'.format([track.track_id for track in activated_stracks]))for it in u_unconfirmed:track = unconfirmed[it]track.mark_removed()removed_stracks.append(track)print('Removed1: {}'.format([track.track_id for track in removed_stracks]))""" Step 4: Init new stracks"""for inew in u_detection:track = detections[inew]if track.score < self.det_thresh:continuetrack.activate(self.kalman_filter, self.frame_id)activated_stracks.append(track)print('Activated3: {}'.format([track.track_id for track in activated_stracks]))""" Step 5: Update state"""for track in self.lost_stracks:if self.frame_id - track.end_frame > self.max_time_lost:print("self.buffer_size : "+str(self.max_time_lost))track.mark_removed()removed_stracks.append(track)print('Removed2: {}'.format([track.track_id for track in removed_stracks]))# print('Ramained match {} s'.format(t4-t3))self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_stracks)self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)print('Lost2: {}'.format([track.track_id for track in lost_stracks]))self.lost_stracks.extend(lost_stracks)self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)print('Lost3: {}'.format([track.track_id for track in lost_stracks]))self.removed_stracks.extend(removed_stracks)self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)# get scores of lost tracksoutput_stracks = [track for track in self.tracked_stracks if track.is_activated]print("detections feature : {}".format([len(i.features) for i in output_stracks]))# print('================Frame {}==============='.format(self.frame_id))print('Activated: {}'.format([track.track_id for track in activated_stracks]))print('Refind: {}'.format([track.track_id for track in refind_stracks]))print('Lost: {}'.format([track.track_id for track in lost_stracks]))print('Removed: {}'.format([track.track_id for track in removed_stracks]))print('output: {}'.format([track.track_id for track in output_stracks]))logger.debug('===========Frame {}=========='.format(self.frame_id))logger.debug('Activated: {}'.format([track.track_id for track in activated_stracks]))logger.debug('Refind: {}'.format([track.track_id for track in refind_stracks]))logger.debug('Lost: {}'.format([track.track_id for track in lost_stracks]))logger.debug('Removed: {}'.format([track.track_id for track in removed_stracks]))return output_stracks




























还没有评论,来说两句吧...