大数据面试之Spark Streaming
大数据面试之Spark Streaming
- Spark Streaming
- 1.1 Spark Streaming工作原理
- 1.1 Spark Streaming如何读取Kafka中数据?
- 1.2 Spark Streaming编写步骤
说明,感谢亮哥长期对我的帮助,此处多篇文章均为亮哥带我整理。以及参考诸多博主的文章。如果侵权,请及时指出,我会立马停止该行为;如有不足之处,还请大佬不吝指教,以期共同进步。
1. Spark Streaming
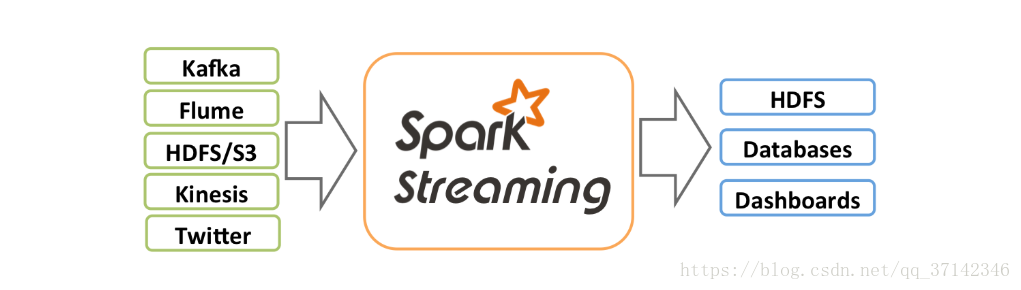
Spark Streaming是Spark Core的扩展应用,它具有可扩展,高吞吐量,对于流数据的可容错性等特点。可以监控来自Kafka,Flumn,HDFS。Kinesis,Twitter,ZeroMQ或者Scoket套接字的数据通过复杂的算法以及一系列的计算分析数据,并且可以将分析结果存入到HDFS文件系统,数据库以及前端页面中。- 高可扩展性,可以运行在上百台机器上(Scales to hundreds of nodes)- 低延迟,可以在秒级别上对数据进行处理(Achieves low latency)- 高可容错性(Efficiently recover from failures)- 能够集成并行计算程序,比如Spark Core(Integrates with batch and interactive processing)
1.1 Spark Streaming工作原理
对于Spark Core它的核心就是RDD,对于Spark Streaming来说,它的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒数将数据流进行批量的划分。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等
参考
参考
1.1 Spark Streaming如何读取Kafka中数据?
一种是利用接收器(receiver)和kafaka的高层API实现一种是不利用接收器,直接用kafka底层的API来实现(spark1.3以后引入)Receiver 方式Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。object KafkaRecciver {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]")val ssc = new StreamingContext(conf, Seconds(5))ssc.checkpoint("hdfs://bigdata111:9000/checkpoint")//创建kafka对象 生产者 和消费者//模式1 采取的是 receiver 方式 reciver 每次只能读取一条记录val topic = Map("mydemo2" -> 1)//直接读取的方式 由于kafka 是分布式消息系统需要依赖Zookeeperval data = KafkaUtils.createStream(ssc, "192.168.128.111:2181", "mygroup", topic, StorageLevel.MEMORY_AND_DISK)//数据累计计算val updateFunc =(curVal:Seq[Int],preVal:Option[Int])=>{//进行数据统计当前值加上之前的值var total = curVal.sum//最初的值应该是0var previous = preVal.getOrElse(0)//Some 代表最终的返回值Some(total+previous)}val result = data.map(_._2).flatMap(_.split(" ")).map(word=>(word,1)).updateStateByKey(updateFunc).print()//启动sscssc.start()ssc.awaitTermination()}Direct方式这种新的直接方式,是在Spark1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。object KafkaDirector {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)//构建conf ssc 对象val conf = new SparkConf().setAppName("Kafka_director").setMaster("local[2]")val ssc = new StreamingContext(conf,Seconds(3))//设置数据检查点进行累计统计单词ssc.checkpoint("hdfs://192.168.128.111:9000/checkpoint")//kafka 需要Zookeeper 需要消费者组val topics = Set("mydemo2")// broker的原信息 ip地址以及端口号val kafkaPrams = Map[String,String]("metadata.broker.list" -> "192.168.128.111:9092")// 数据的输入了类型 数据的解码类型val data = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc, kafkaPrams, topics)val updateFunc =(curVal:Seq[Int],preVal:Option[Int])=>{//进行数据统计当前值加上之前的值var total = curVal.sum//最初的值应该是0var previous = preVal.getOrElse(0)//Some 代表最终的但会值Some(total+previous)}//统计结果val result = data.map(_._2).flatMap(_.split(" ")).map(word=>(word,1)).updateStateByKey(updateFunc).print()//启动程序ssc.start()ssc.awaitTermination()}
参考
参考
参考
参考
参考
1.2 Spark Streaming编写步骤
1. 通过创建输入DStream来定义输入源。2. 通过对DStream应用转换操作和输出操作来丁意思流计算3. 用streamingContext.start()来开始接收数据和处理流程4. 通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)6. 可以通过streamingContext.stop()来手动结束流计算进程






























![java工程师进阶JVM[1]-Java内存结构](https://image.dandelioncloud.cn/images/20221123/51fce8e20e194db0ae600618ec5ff1d3.png "java工程师进阶JVM[1]-Java内存结构")



还没有评论,来说两句吧...