BP反向传播详细推导
BP神经网络是反向传播算法,他是一个非线性的前馈神经网络。由于网络参数需要更新,反向指的是参数梯度的反向传播,输入向前传播。非线性是因为神经元的激活函数是一个非线性可导的sigmoid函数。先来看看神经元的激活函数,即sigmoid函数:
该函数的特点是:
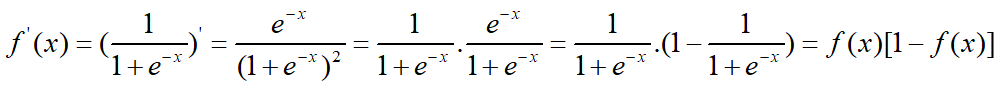
其图像为:
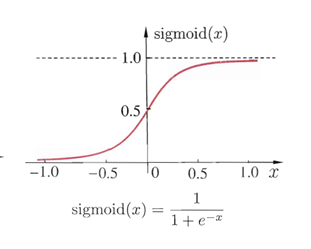
Sigmoid函数把可能在较大范围内变化的输入值挤压到(0,1)的范围内,并且该函数是可导的。当然,sigmoid函数只是神经元激活函数的一种,但却是最常用的一种激活函数。
首先,我们来看看BP算法的真面目。给定一个训练集(含有m个样本)。
,其中
表示输入由 d 个属性描述(特征维度为d),
表示输出为
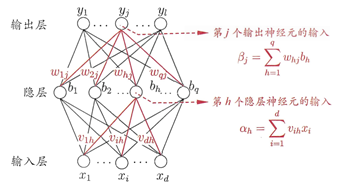
维实值向量(l 个类别)。为了便于讨论,下图给出了一个拥有
个输入神经元,
个输出神经元和
个隐藏神经元的多层前馈神经网络。该网络包含一个输出层,一个隐藏层,一个输出层。其中隐藏层的阈值是
,输出层的阈值是
。
现在设定符号标准:
:输入层第i个神经元和隐藏层第h个神经元之间连接的权值
:隐藏层第h个神经元和输出层第j个神经元之间连接的权值
:隐藏层第h个神经元的输入,
是输入层的第i个输入
:输出层第j个神经元的输入,
是输出层的输入,也就是隐藏层的输出
:隐藏层第h个神经元的输出,即输出层的第h个输入,
是隐藏层第h个神经元的阈值(偏置)
:第k个输入神经元的网络输出
,
是输出层的阈值(偏置)
:输出层第j个神经元的理想输出
根据神经网路结构图可以看出网络中要确定的变量个数是 个,其中输入层到隐藏层有d*q个权值变量,隐藏层到输出层有
个权值变量,还包括q个隐藏层神经元阈值和 l 个输出层神经元阈值。
则网络在上的均方误差为:
BP神经网络的思想是根据均方误差,来调整每条连接线的权值和阈值(偏置)。从而使均方误差达到一个可以接受的值。
阈值是用来衡量是否可以结束神经网络算法的一个条件(当然还有其他的结束条件,达到一定的迭代次数,误差降低到某一程度。)
下面进行神经网络算法的推倒过程:(采用随机梯度下降法)
第k个输出样本在输出层的均方误差为:
现在以隐藏层到输出层的权值和阈值(偏置)调整方案为例:
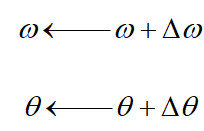
定义: ,即用梯度下降法来调整权值的变化,其中负号表示梯度下降的方向,
表示学习效率(或叫做调整步长),一般取(0,1)。
因为: 对输出层的输入
和输出层的输出
都有影响,
所以:
而 ,
。因为
是经过输出层神经元激活函数后得到输出
带入上述公式得
令:
则: ——》这是
的调整方法:
现在推倒 的调整方法:
到此,权重和阈值的调整方法都已经知道了:
现在我们再来推倒一下,因为
的影响路径:
其中:
令:
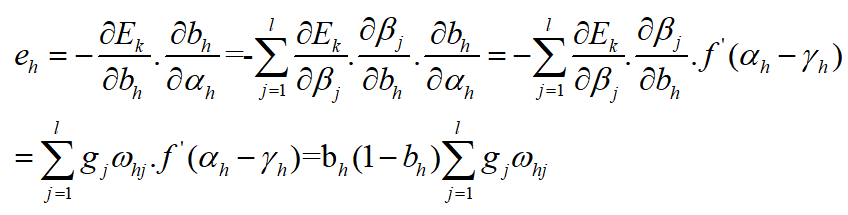
注意第二个等号的理解:即第k个样本在输出层的误差是输出层的 神经元的误差和,那么
, 是隐藏层的第h个输出,即输出层的第h个输入(还没乘以权值),这个输入对输出层的每一个神经元都有影响,所以有一个求和的过程。
所以:
同理可得:
所谓误差的反向传播(我的理解):根据公式即可发现,每一层权值和偏置的调整,都跟其直接相连接的下一次输出值的误差有关。即,输出的结果,对于权值和偏置的调整是有影响的。这也是,BP模型权值和偏置调整公式的定义。
现在的几个问题:
1,梯度的几何意义?
2,的变化,是正数?是负数?正数代表的含义?负数代表的含义?
3,随机梯度下降和标准梯度下降?
4,解决过拟合问题?
5, 的大小怎么定?
问题1:

函数在某一点的梯度,垂直于该点的等值面,指向函数增大的方向。
问题2: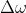 就是梯度乘上一个因子
就是梯度乘上一个因子
问题3:标准梯度下降和随机梯度下降的关键区别是:
(1) 标准梯度下降是在权值更新前对所有样本汇总误差,而随机梯度下降的权值是通过考察每一个训练样本实例来更新。
(2) 标准梯度下降因为要对所有样本汇总误差,计算量更大。这样,每一次权值更新比随机梯度下降所用的步长(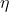 )更大
)更大
(3) 如果误差有多个极小值,随机梯度下降可能避免陷入这些局部极小值。因为采用不同的
而不是
(4) 使用随机梯度下降,可以最小化均方误差。
问题4:迭代次数太少,误差过大,发生欠拟合。迭代次数过多,在训练样本上,误差很小。出现过拟合。权值衰减法。为算法提供一套验证数据集。
问题5: 一般被设定为一个很小的数值,有时候会使其随着权调整次数的增加而衰减。(放慢学习速率,减小步长)。因为在迭代一定次数过后,过大,可能会使梯度下降跳过全局最小值。


































还没有评论,来说两句吧...